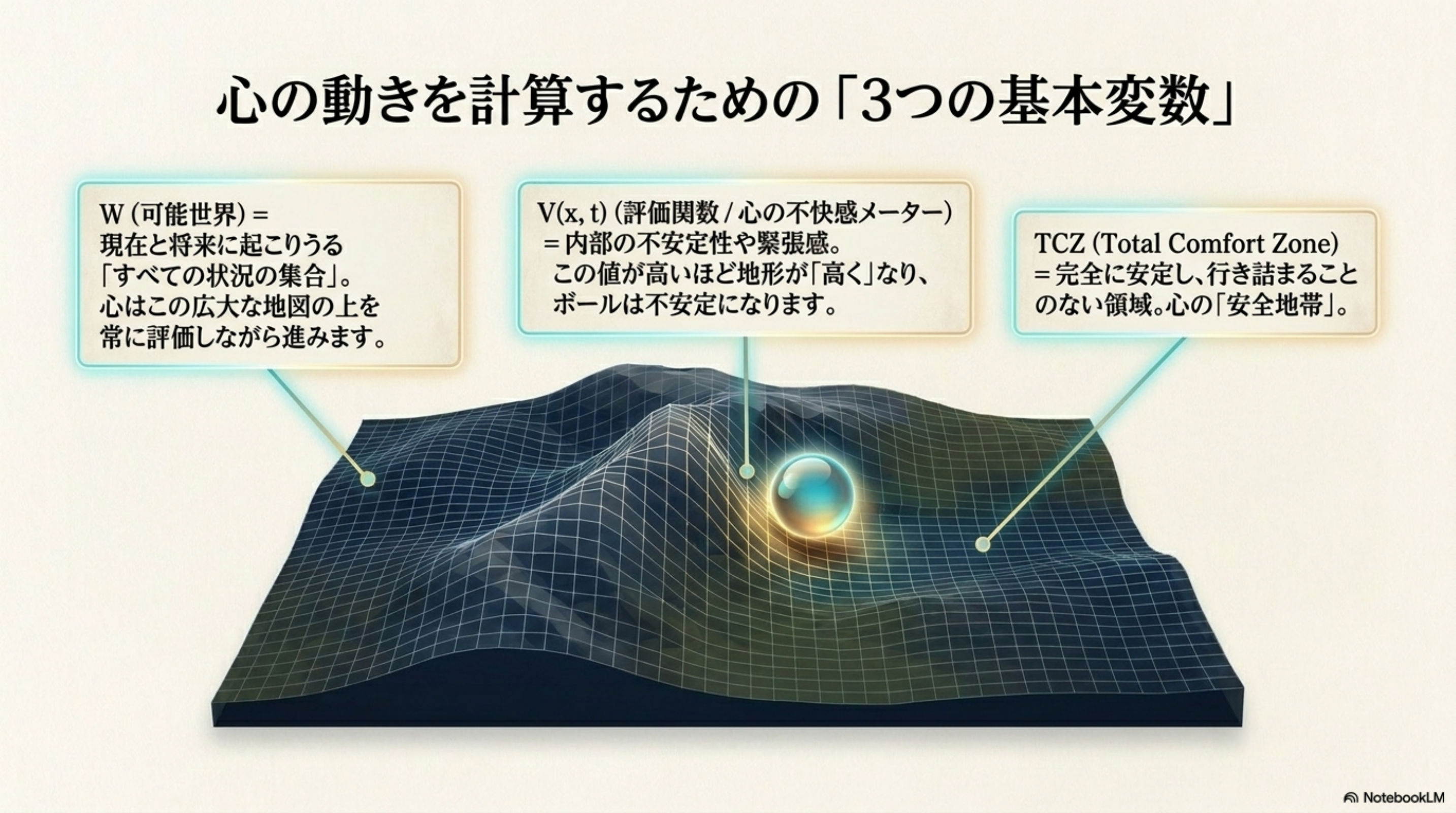
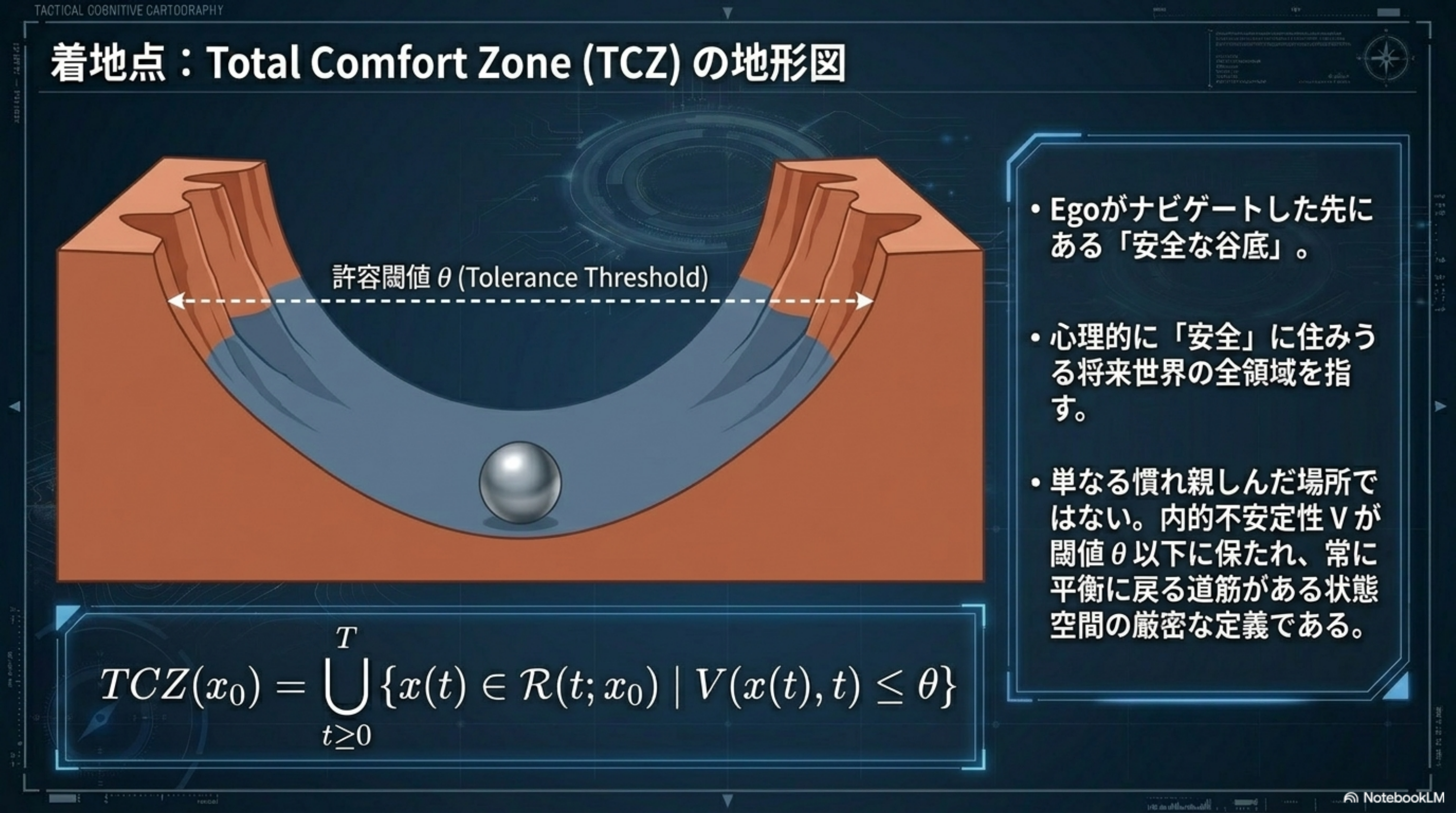
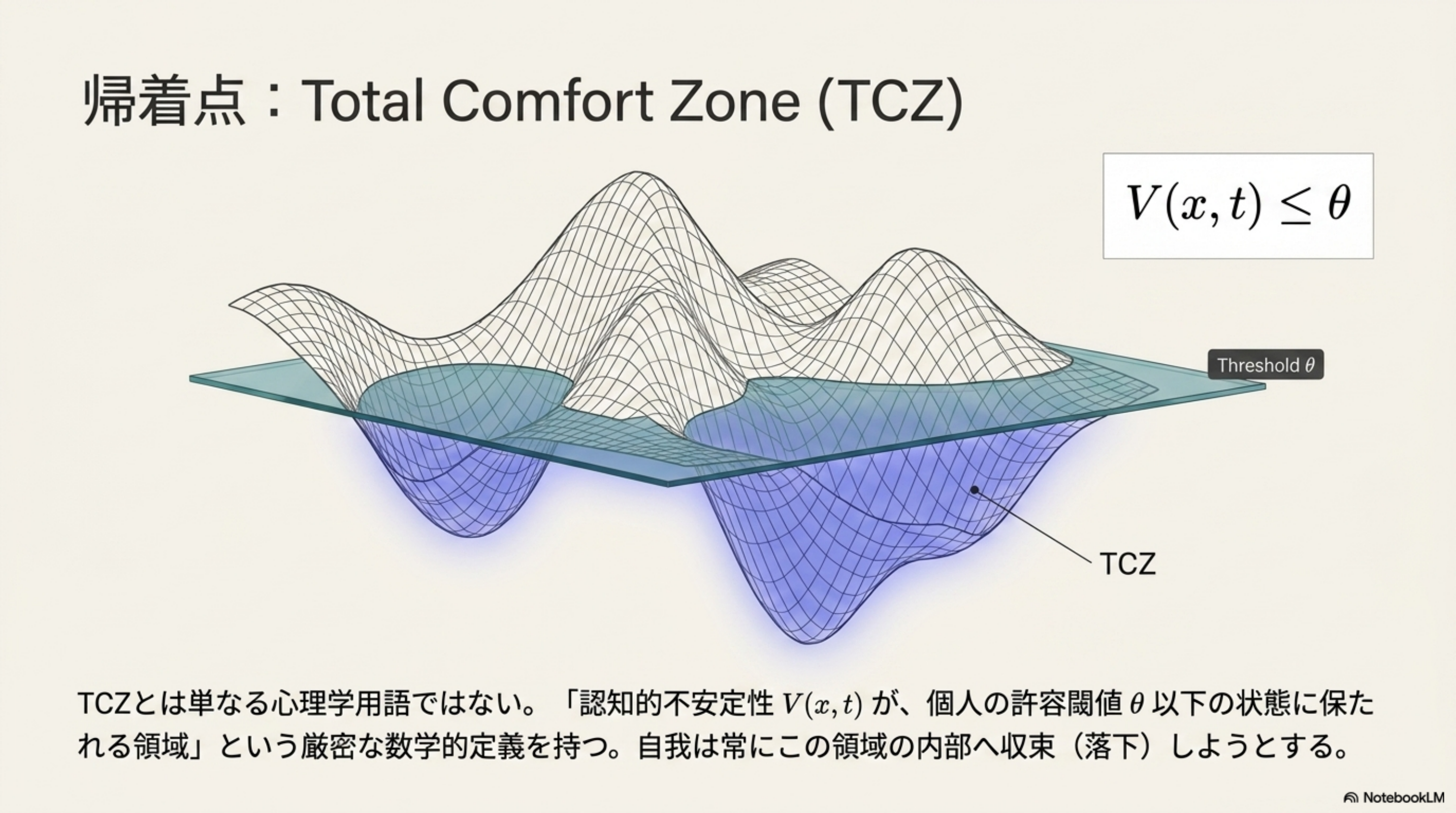
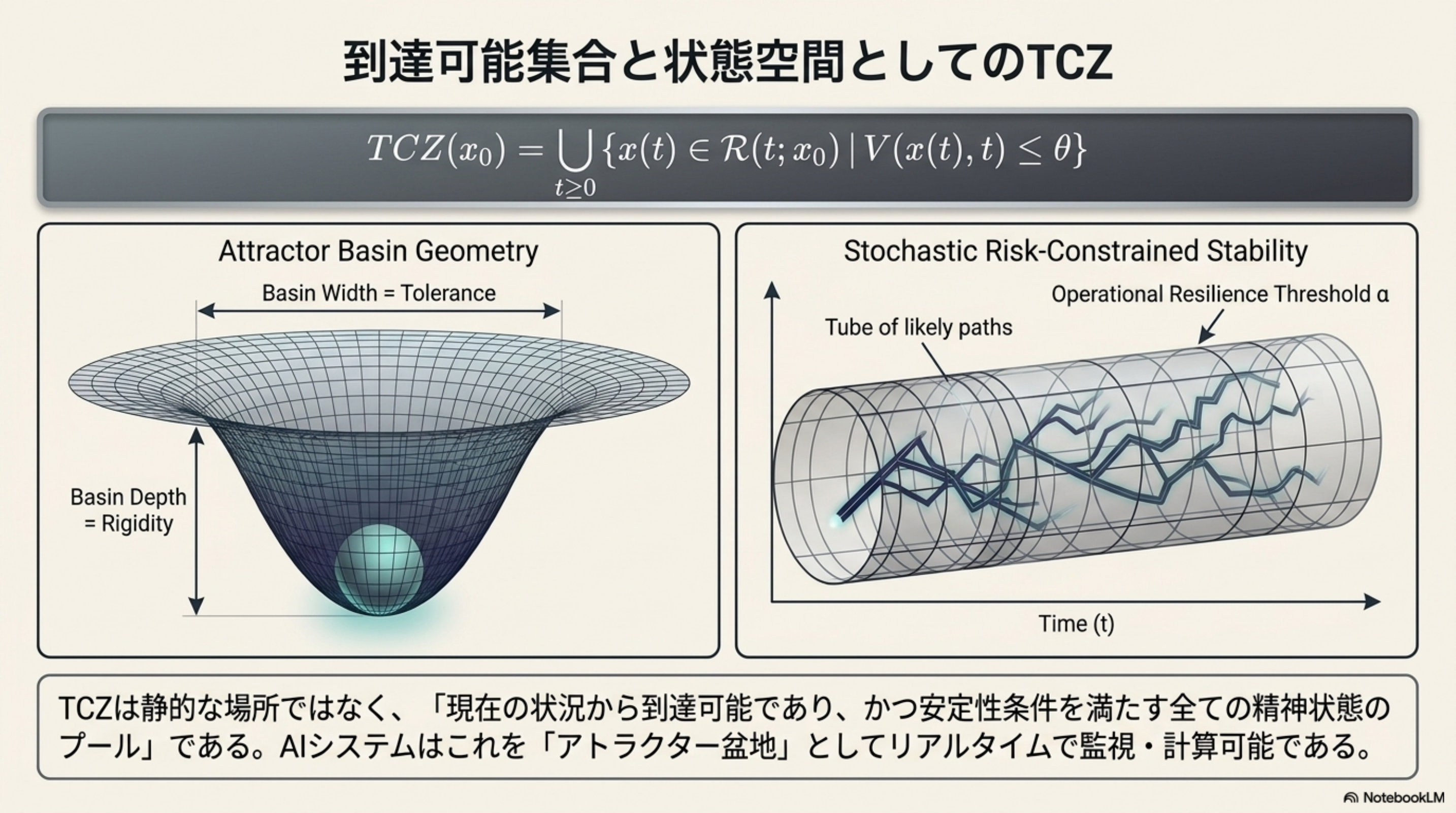
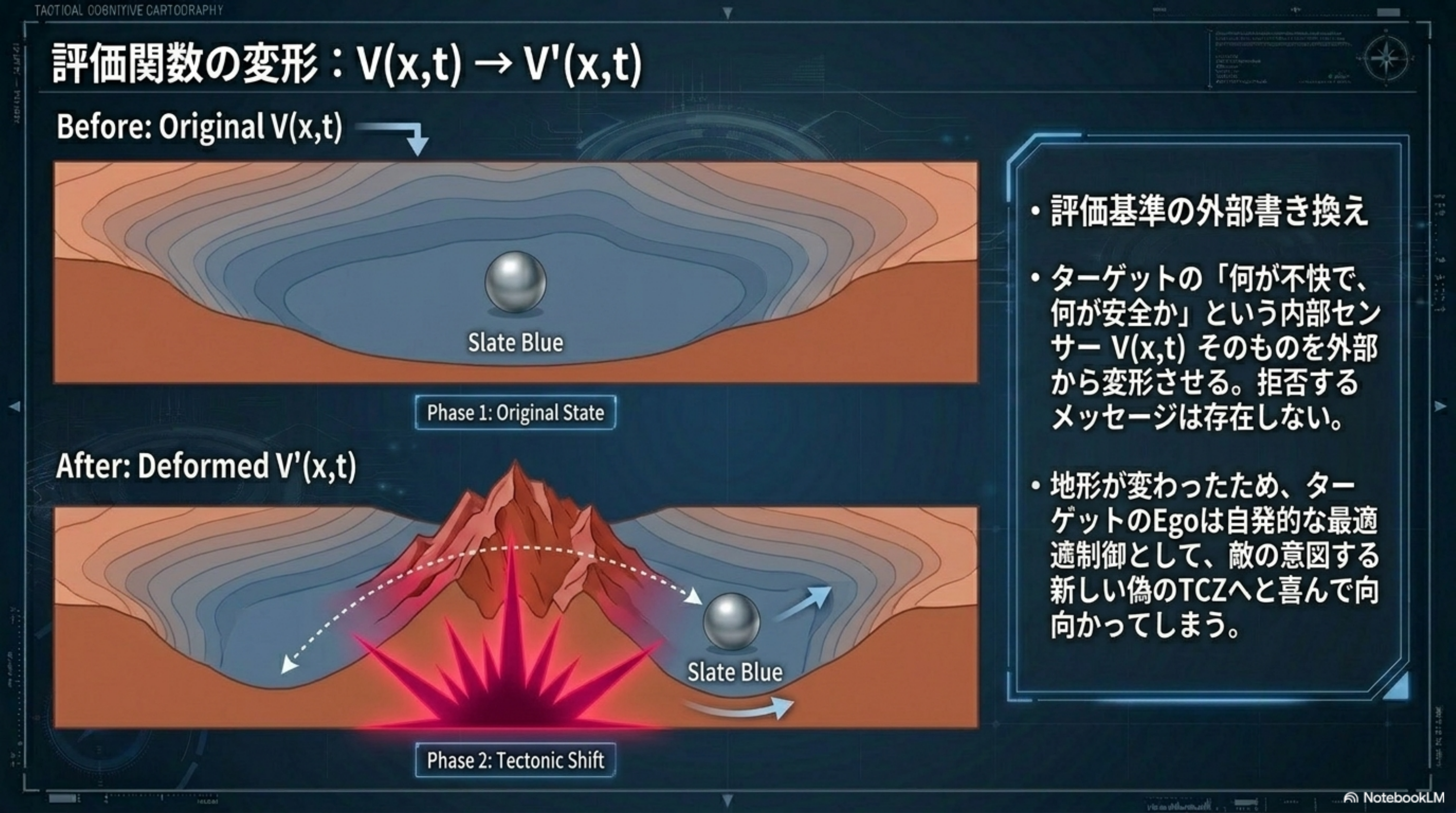
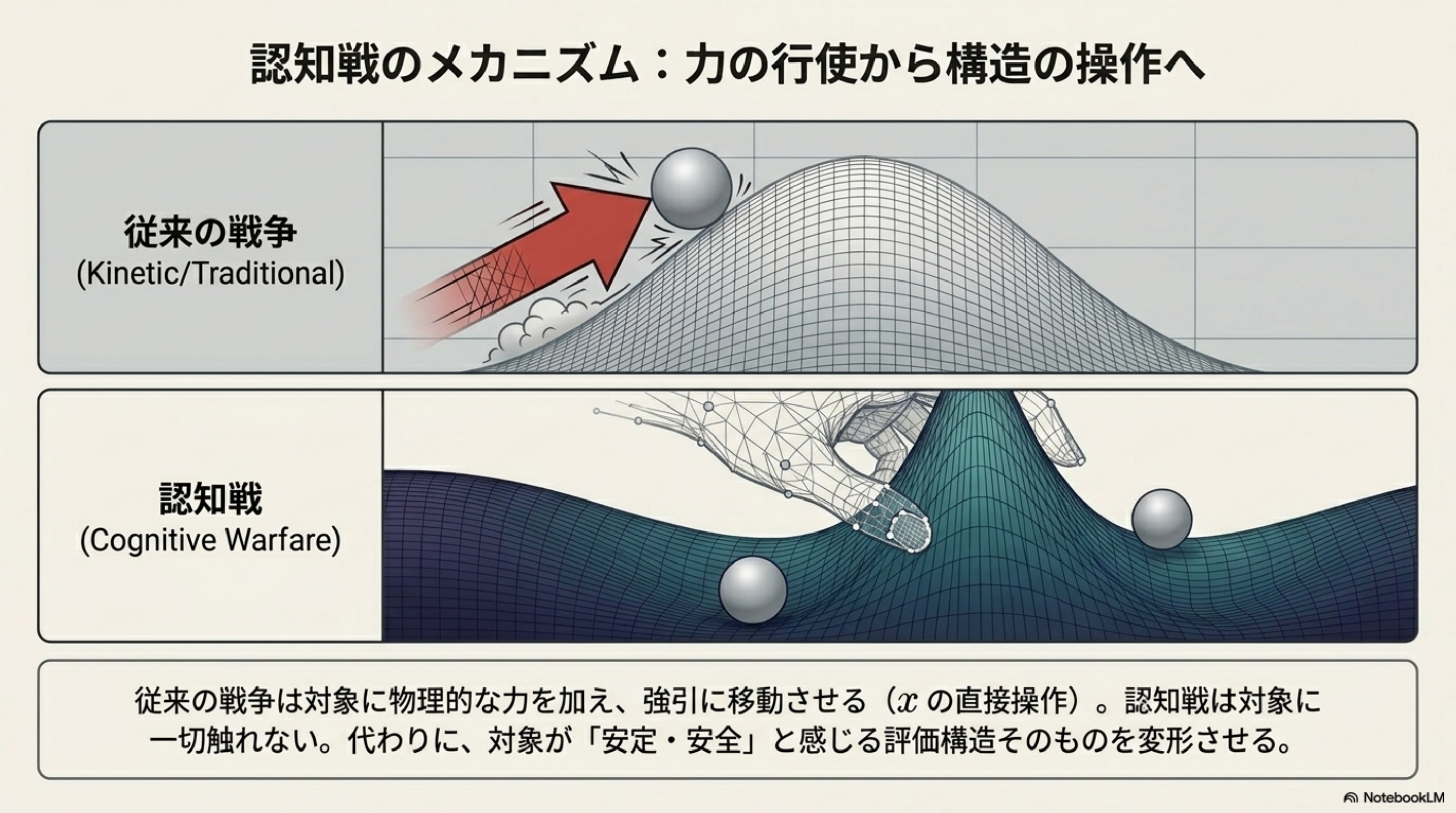
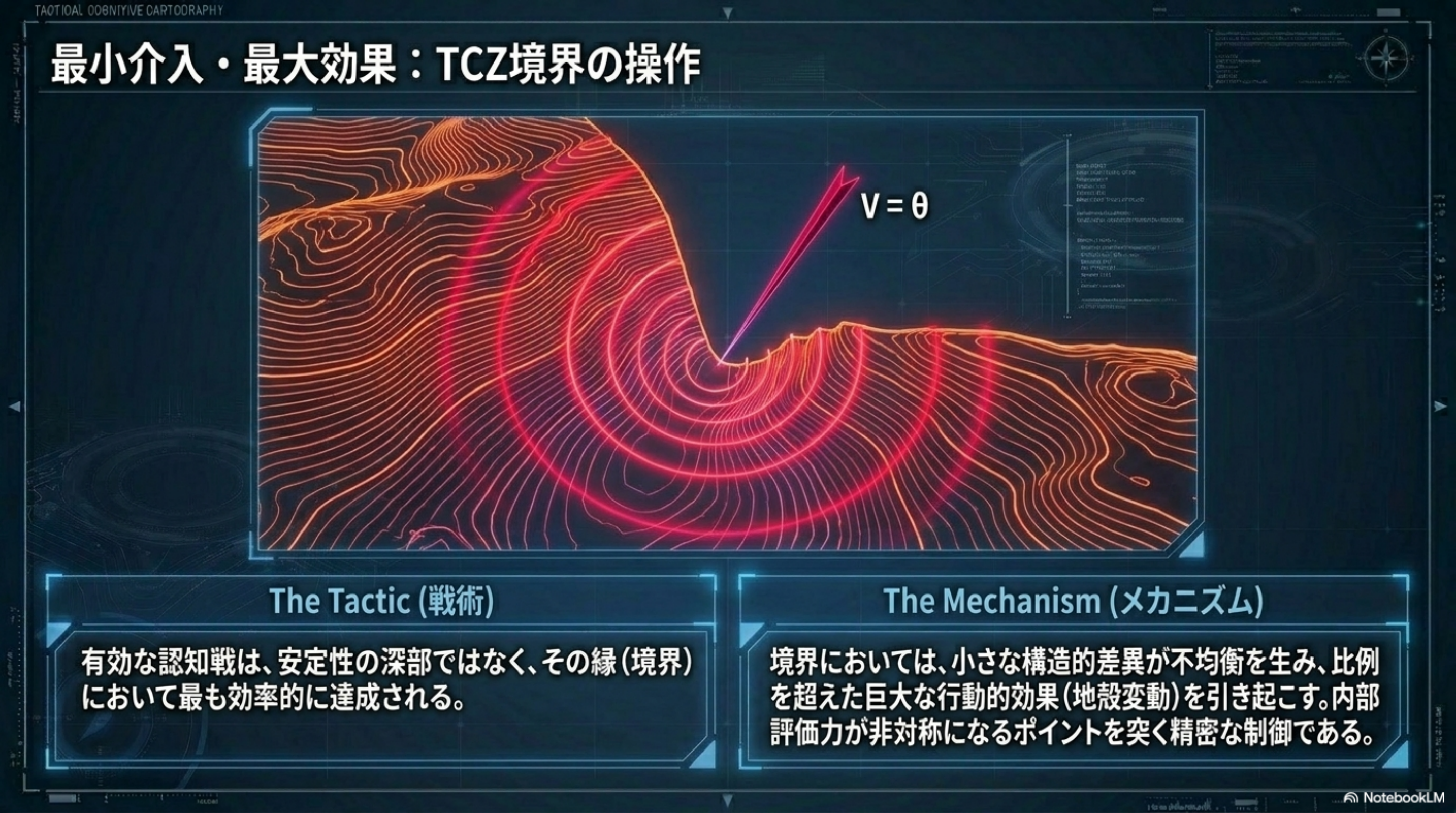
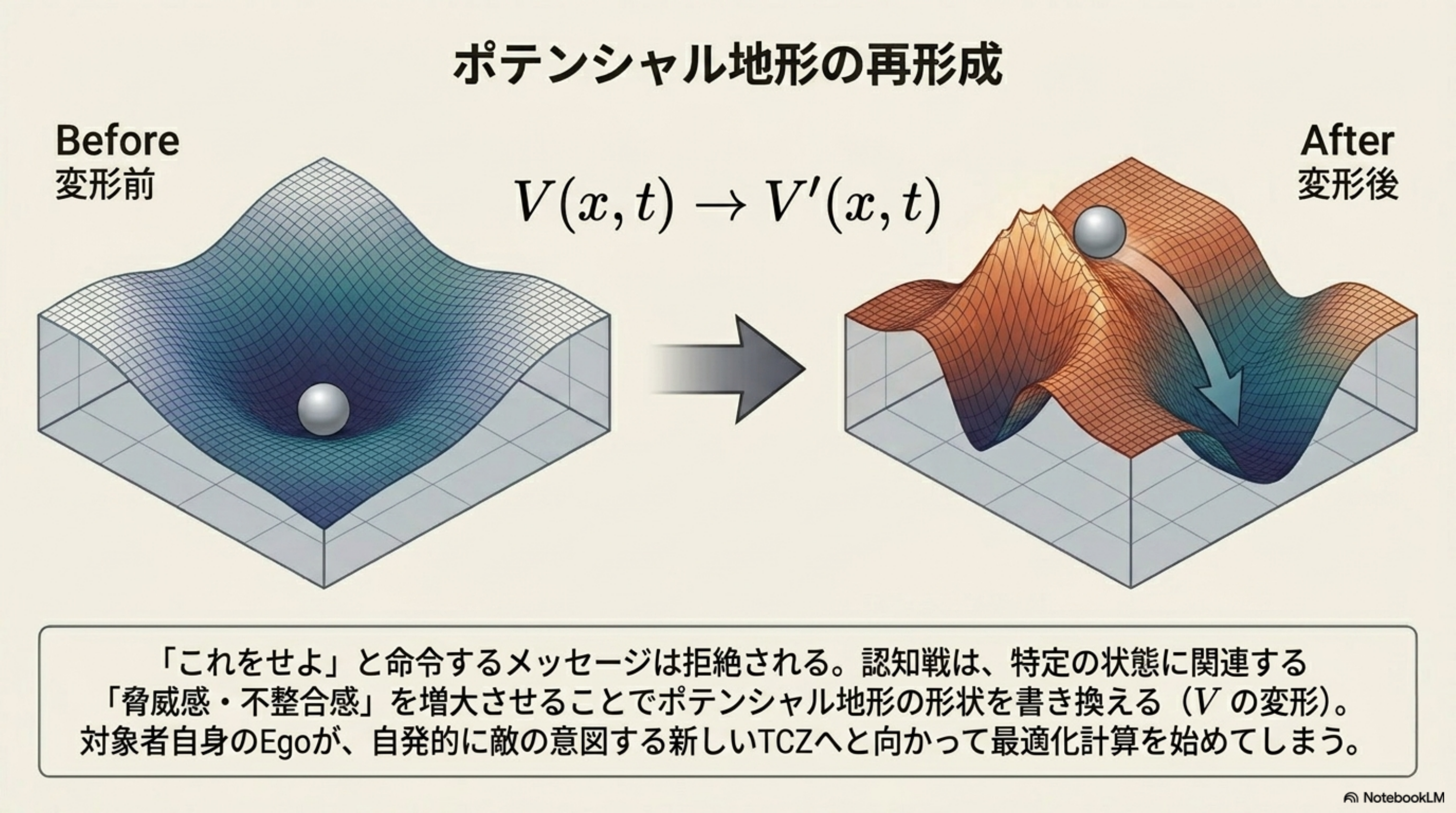
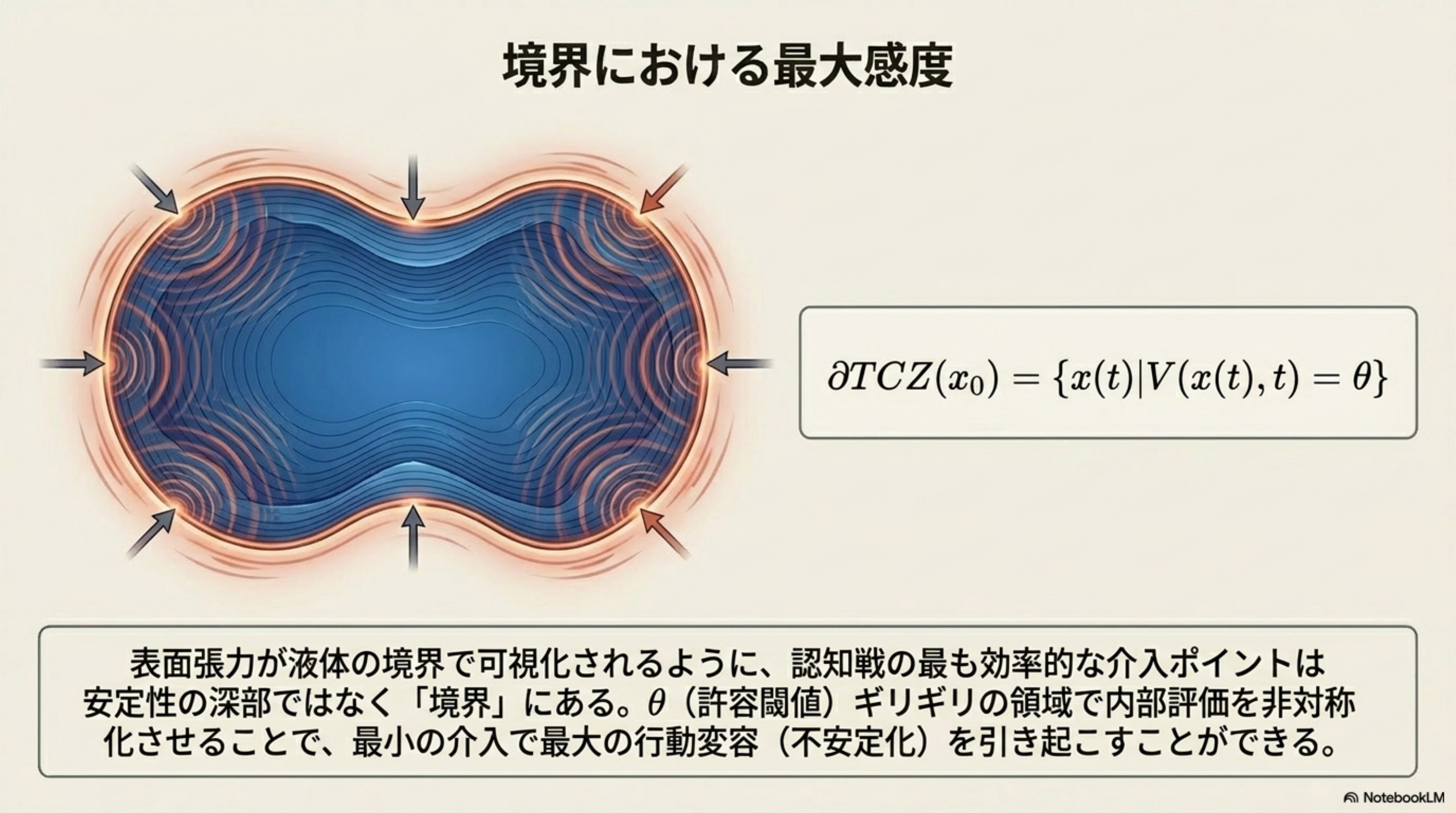
OVERVIEW · 全体俯瞰
8定理体系の骨格
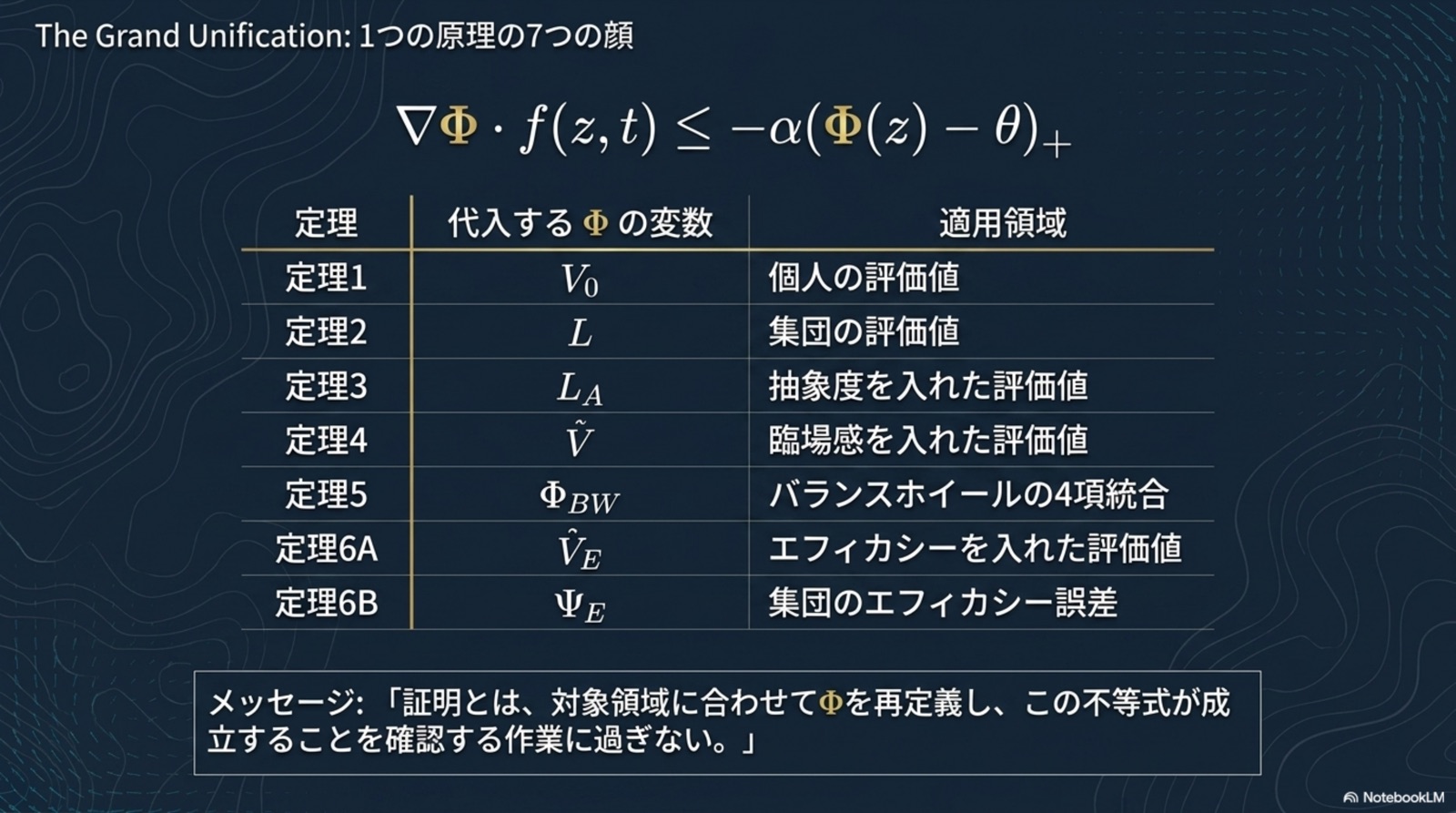
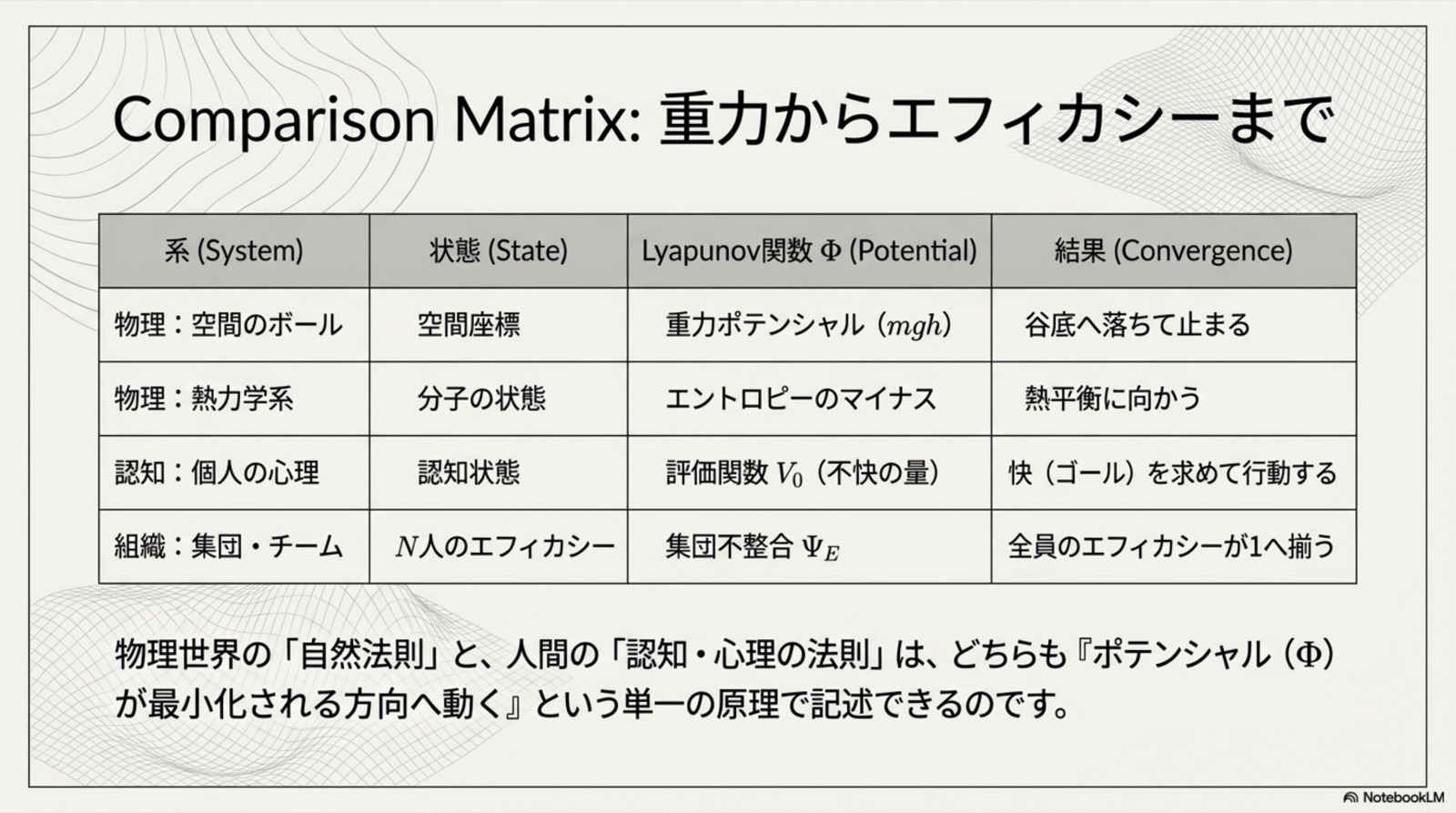
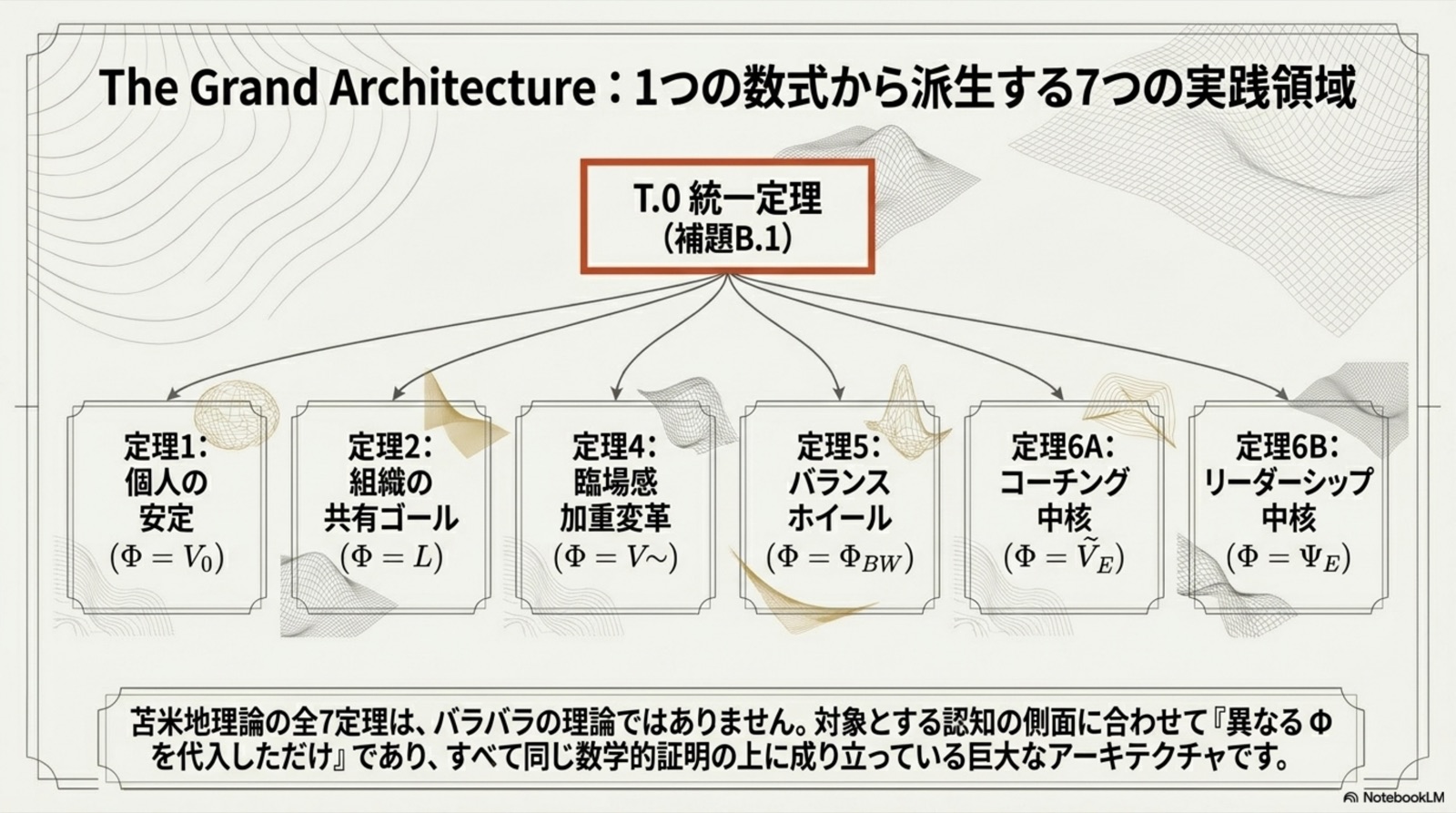
これから読み解くのは、たった一つの補題(B.1)から派生した8つの定理。
個体 → 集団 → 抽象 → 臨場感 → バランスホイール → コーチング → リーダーシップ。
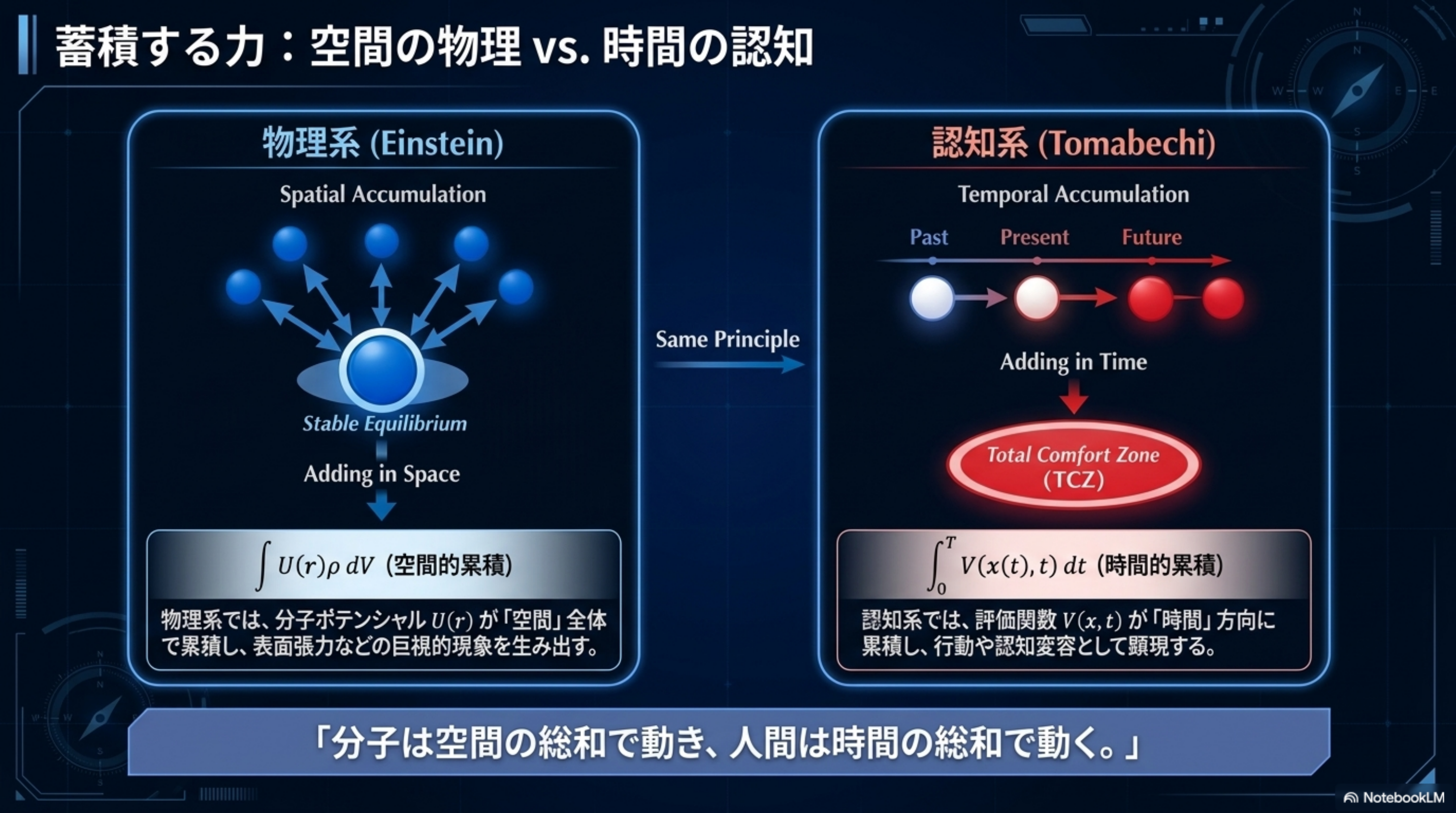
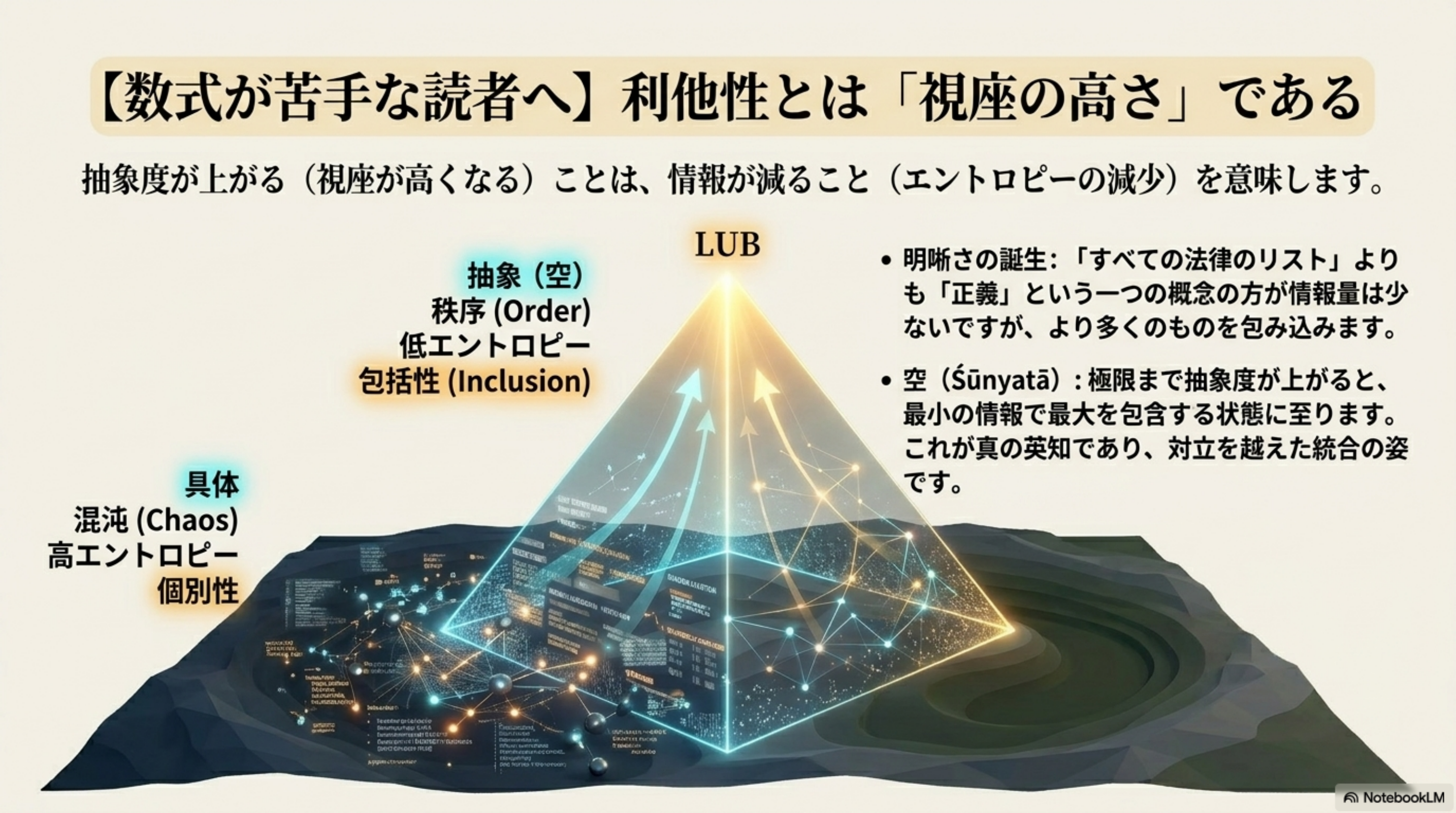
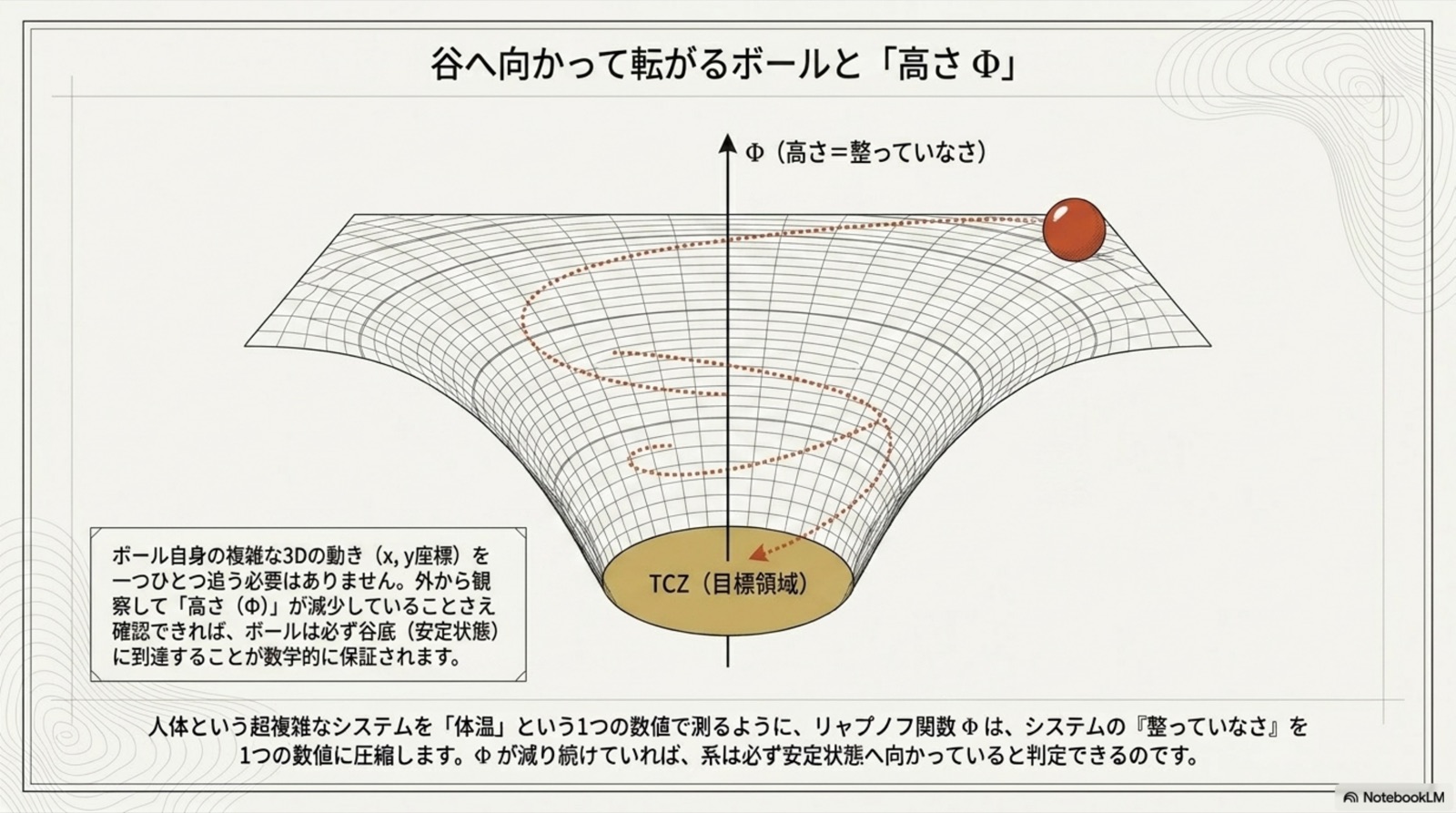
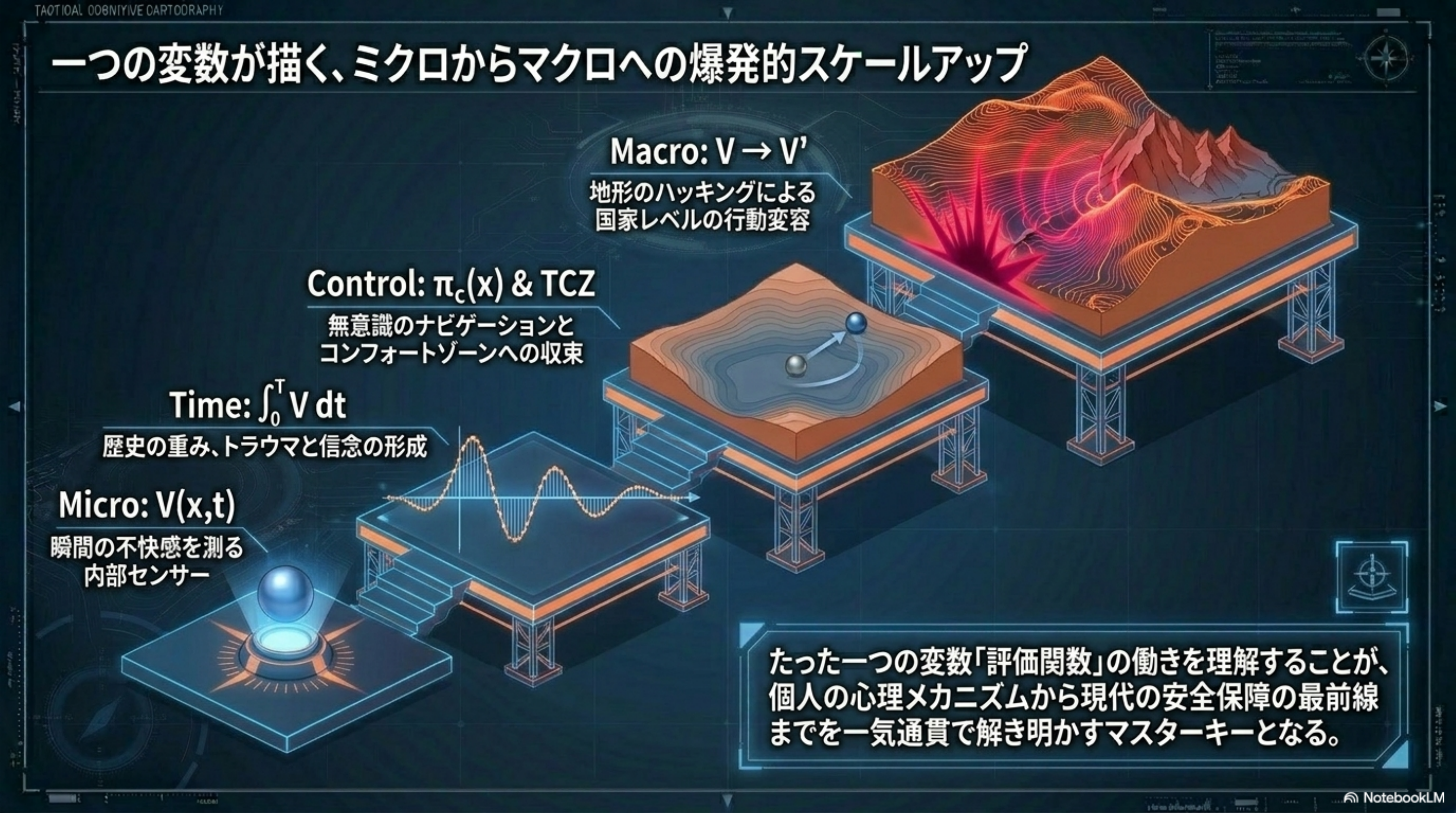
全ては「ポテンシャル下降 ∧ 抽象上昇」という統一双対原理に貫かれている。

OVERVIEW · B.1 統一補題から派生する全7定理 + T.0 統一定理
#
名称
① 制御方策 π(個人視点)
② Lyapunov Φ(系全体)
中核含意
T.0
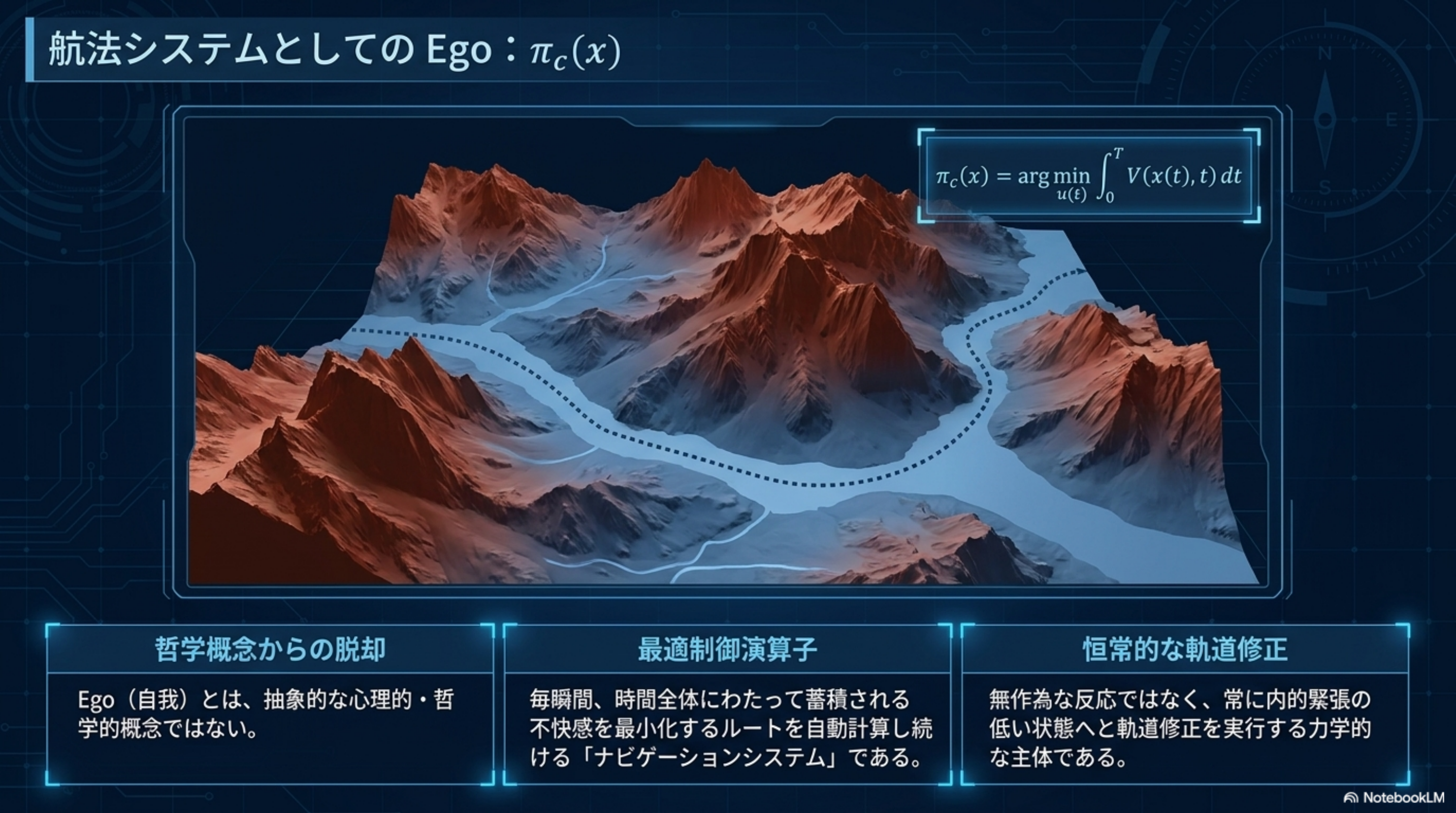
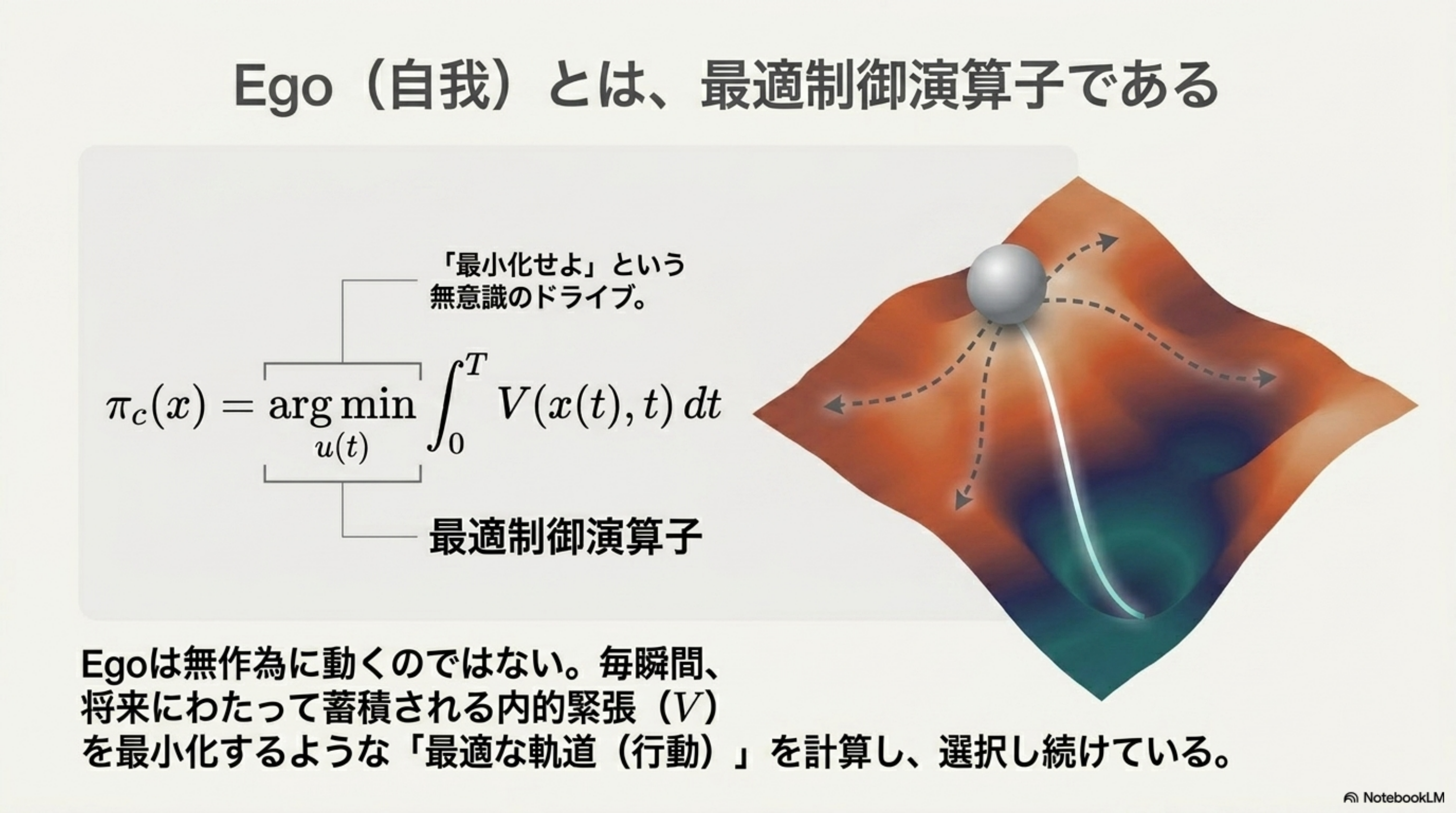
苫米地統一定理
π_c = arg min ∫ V dt
x*(t) → TCZ(x₀)
Self / Ego / TCZ の三言語統一
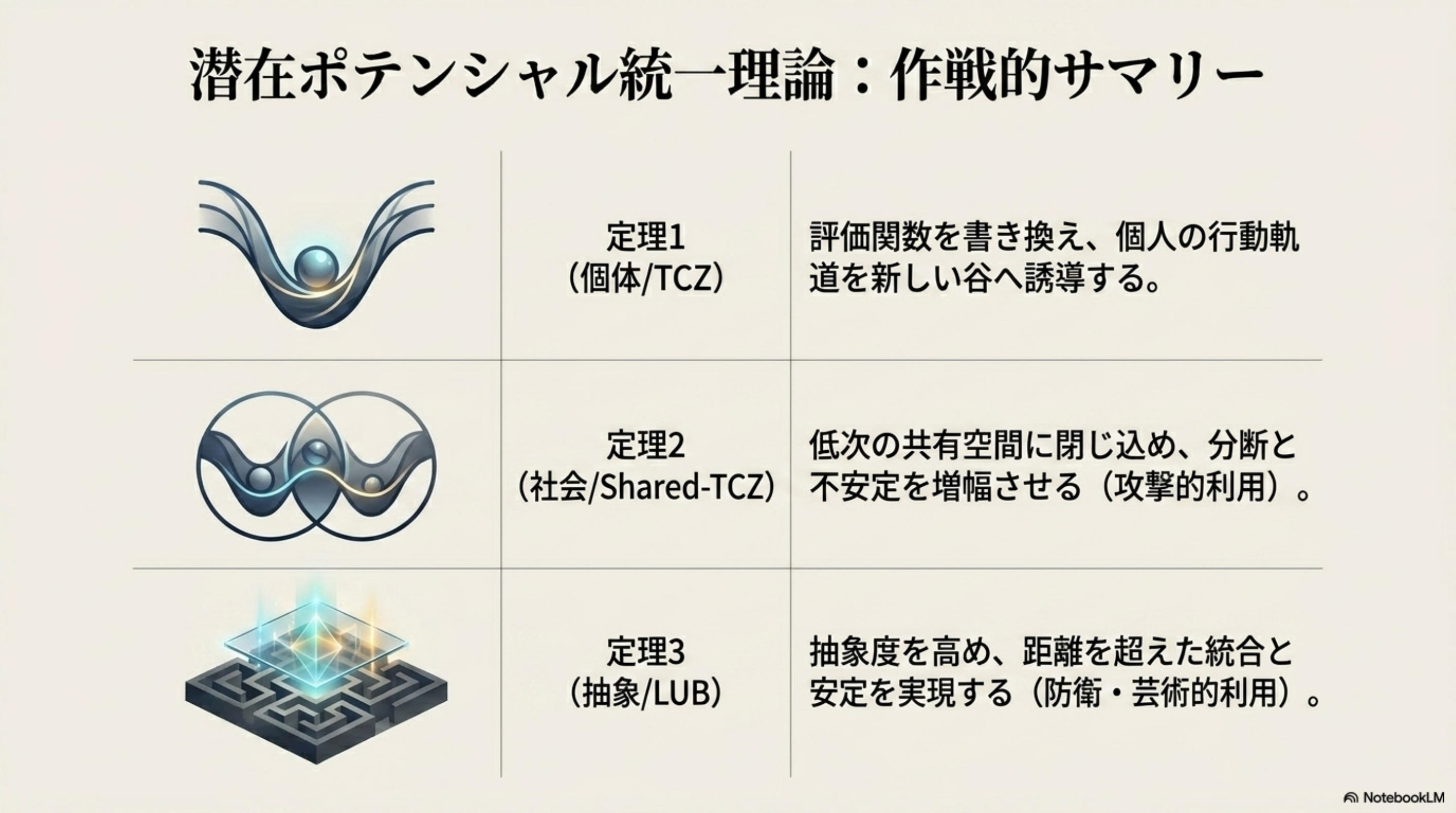
1
個体安定収束
π_c = arg min ∫ V₀ dt
Φ = V₀
個人は累積コスト最小領域へ収束
2
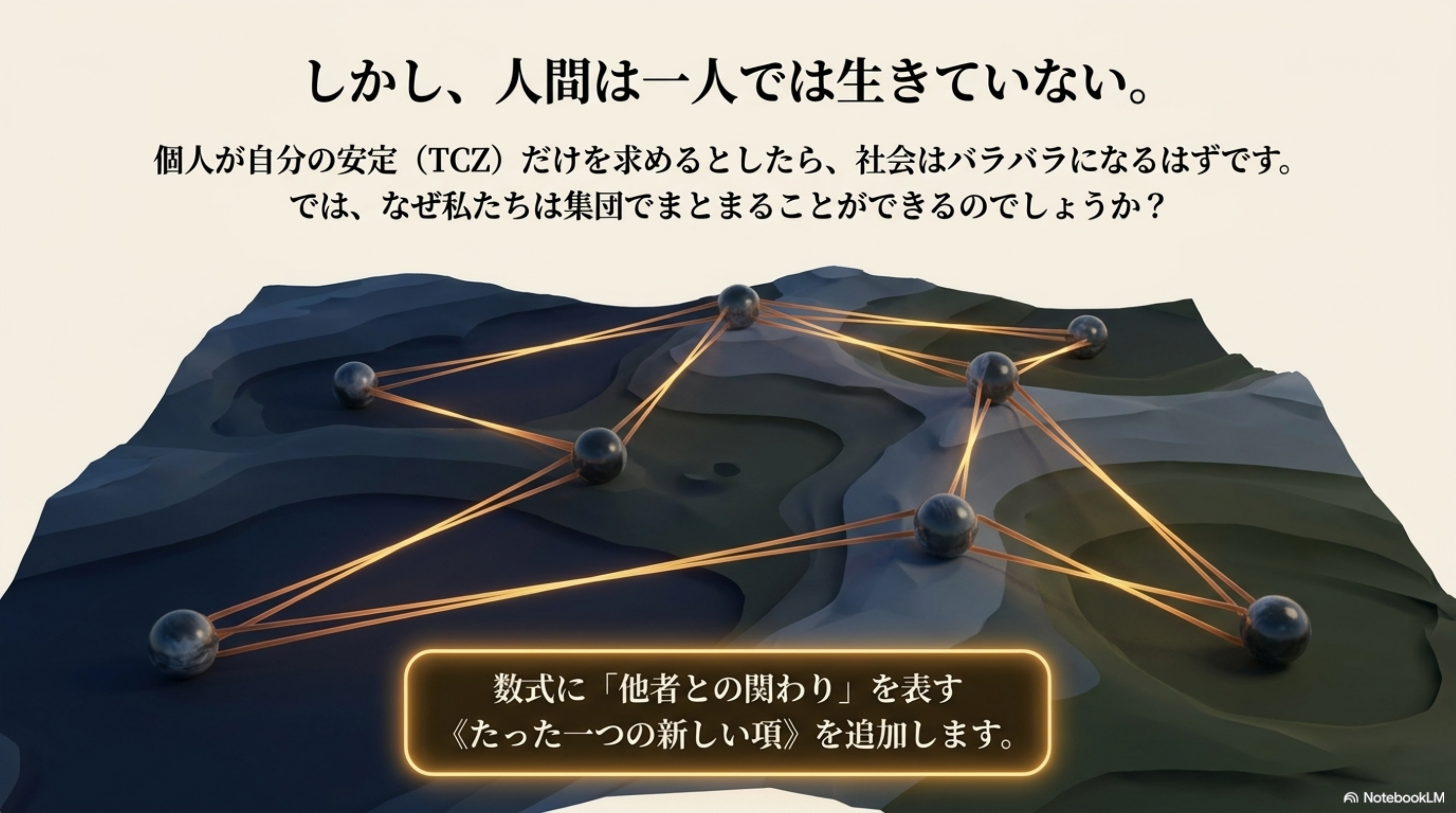
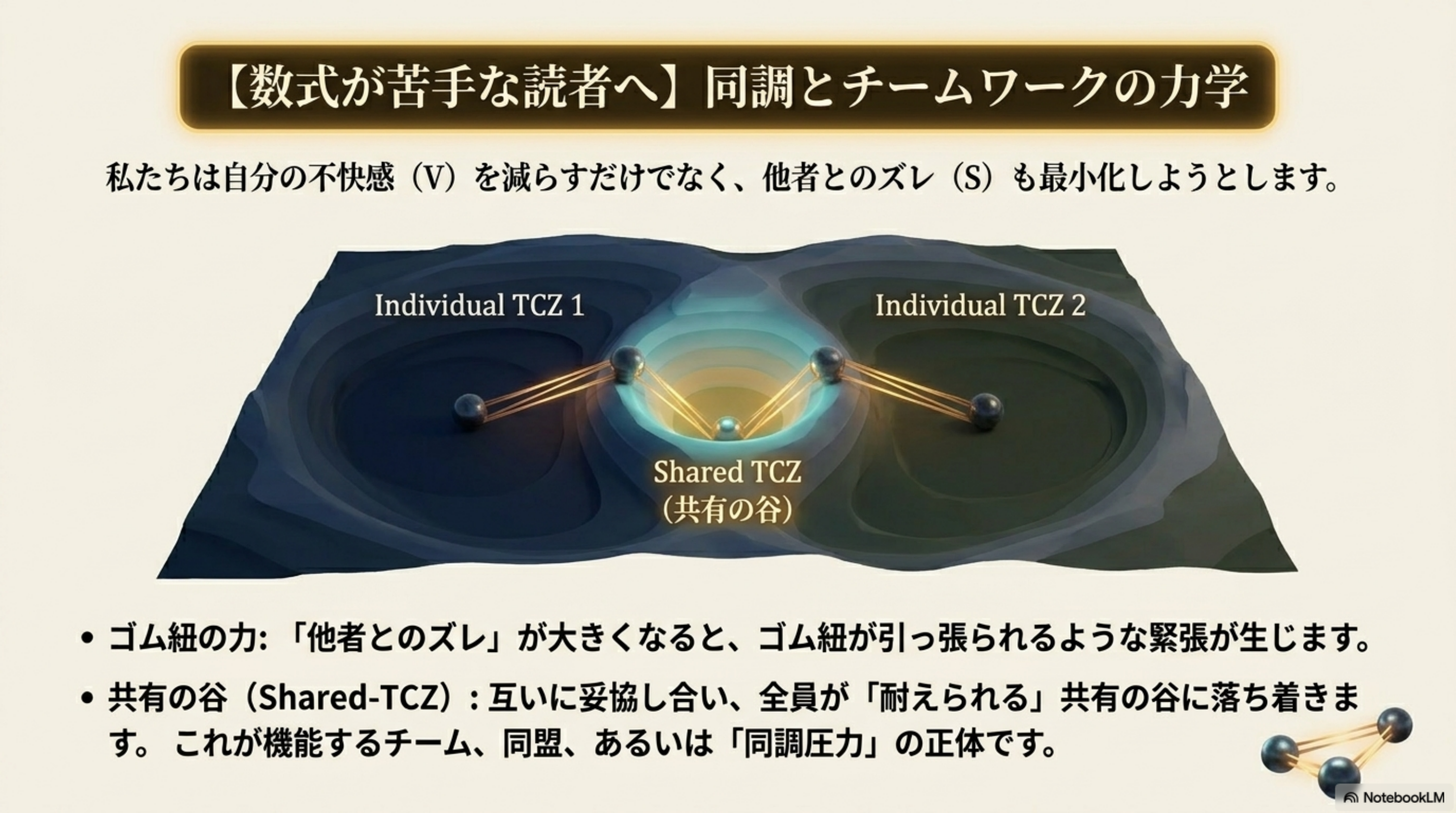
Shared-Alignment 収束
π_i = arg min ∫(V_i + Σγ_ij S_ij) dt
Φ = ℒ (複合)
多主体は共有 TCZ へ収束
3
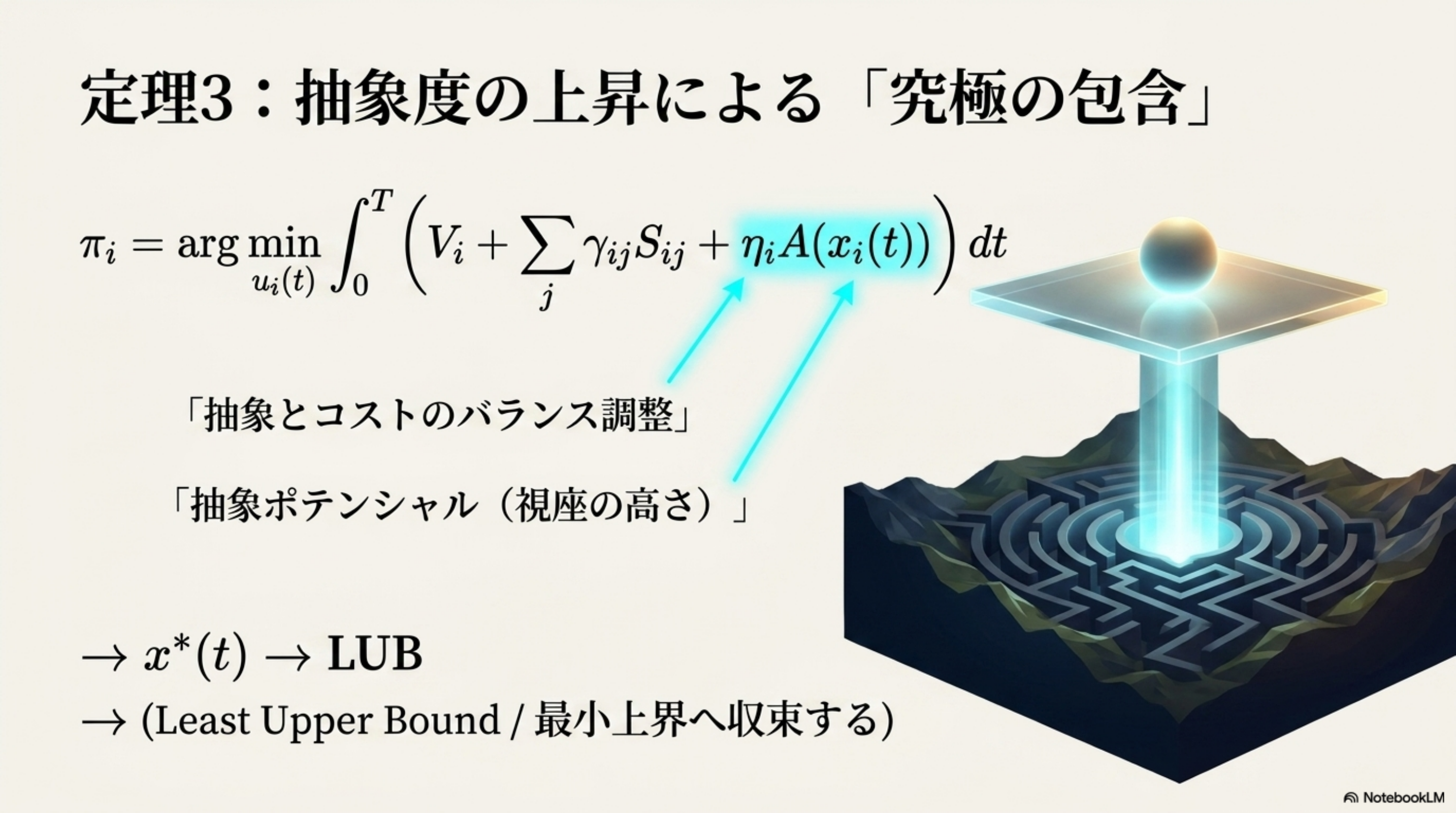
Higher-Purpose 統合
π_i = arg min ∫(V_i + ΣγS + η_i A) dt
Φ = ℒA (抽象拡張)
集団は LUB(最小上界)へ統合
4
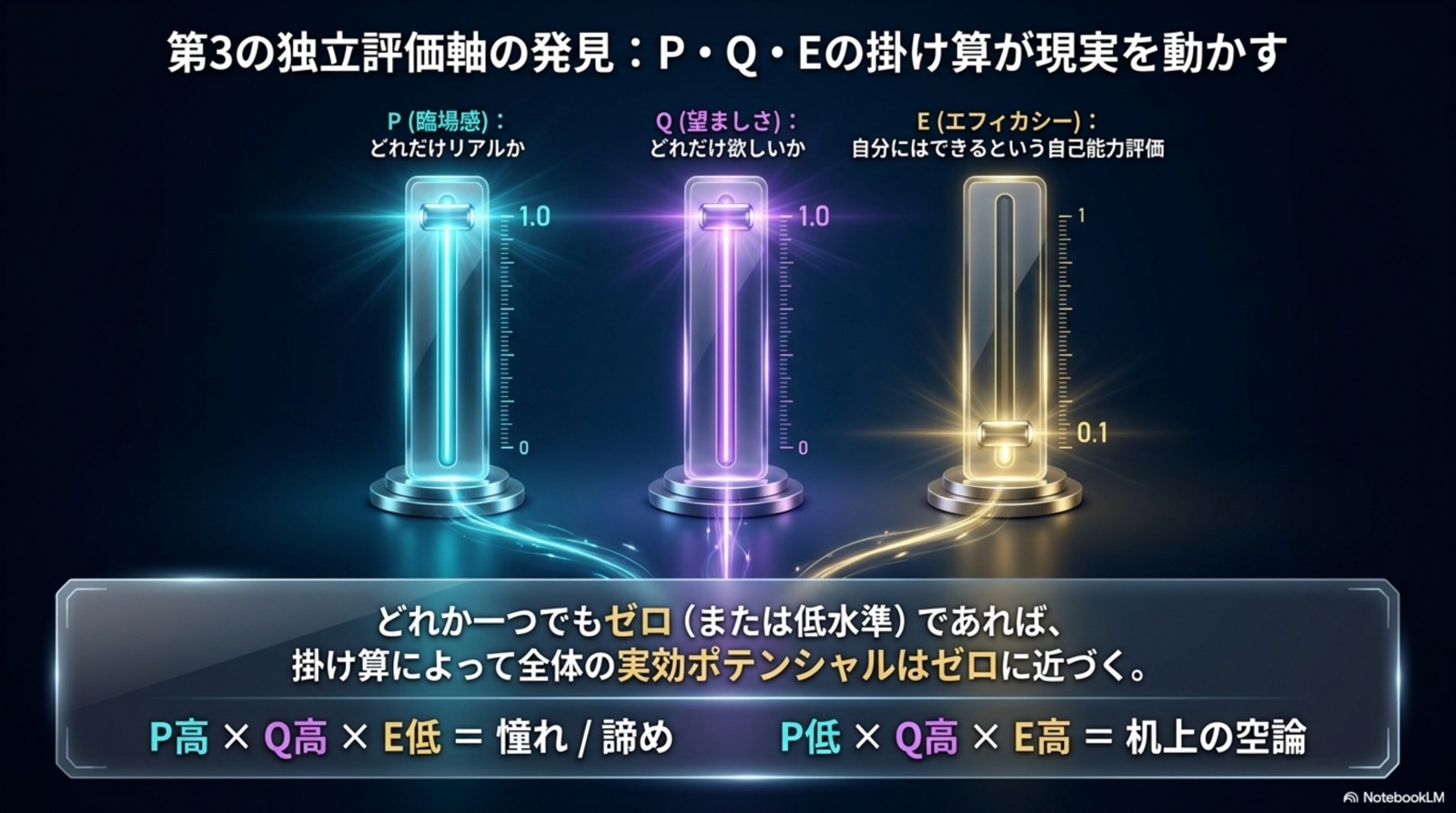
臨場感加重変革(中心式)
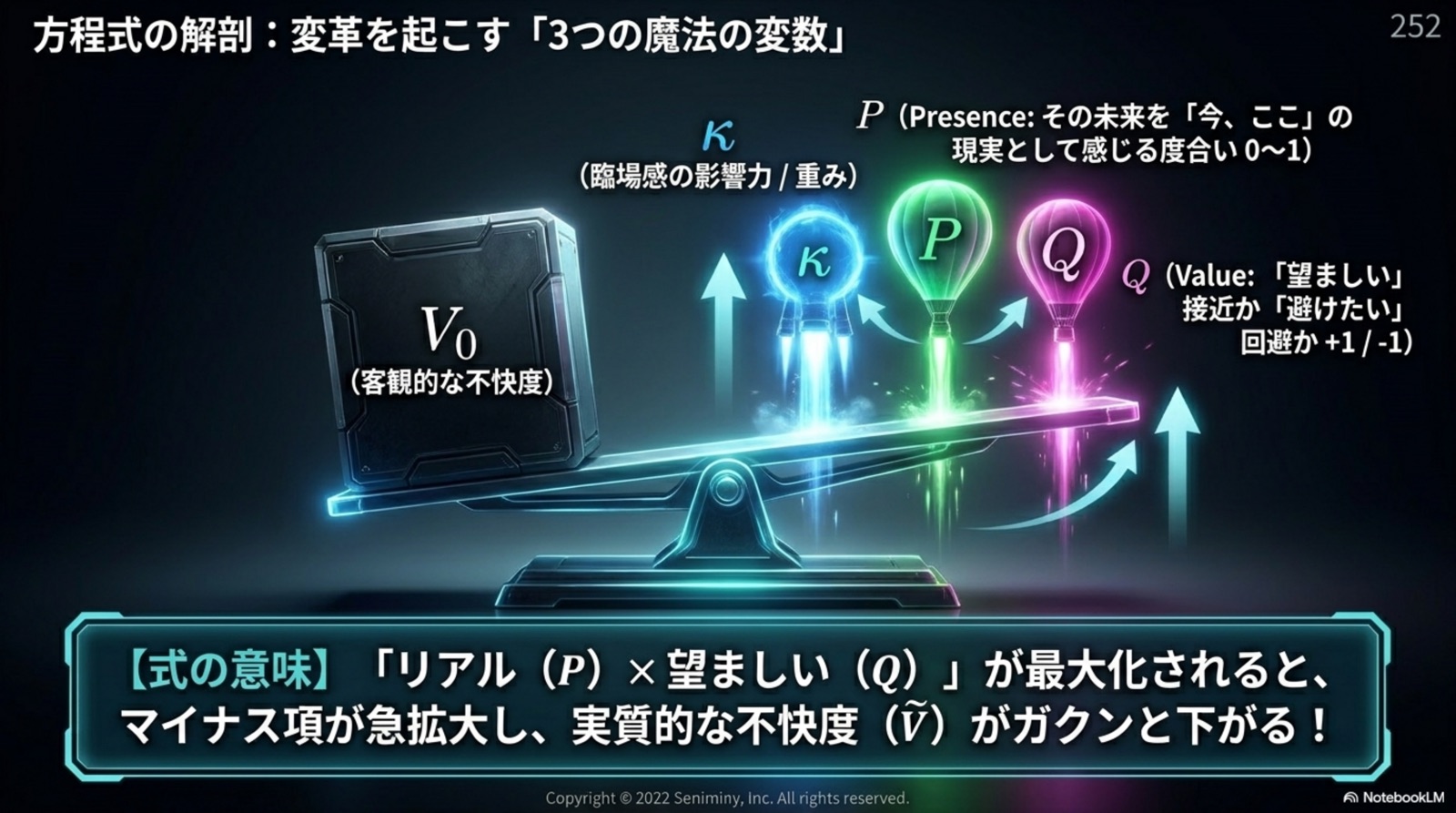
π_c = arg min ∫ Ṽ dt
Φ = Ṽ = V₀ − κPQ
人はリアルに感じる安定世界へ向かう
5
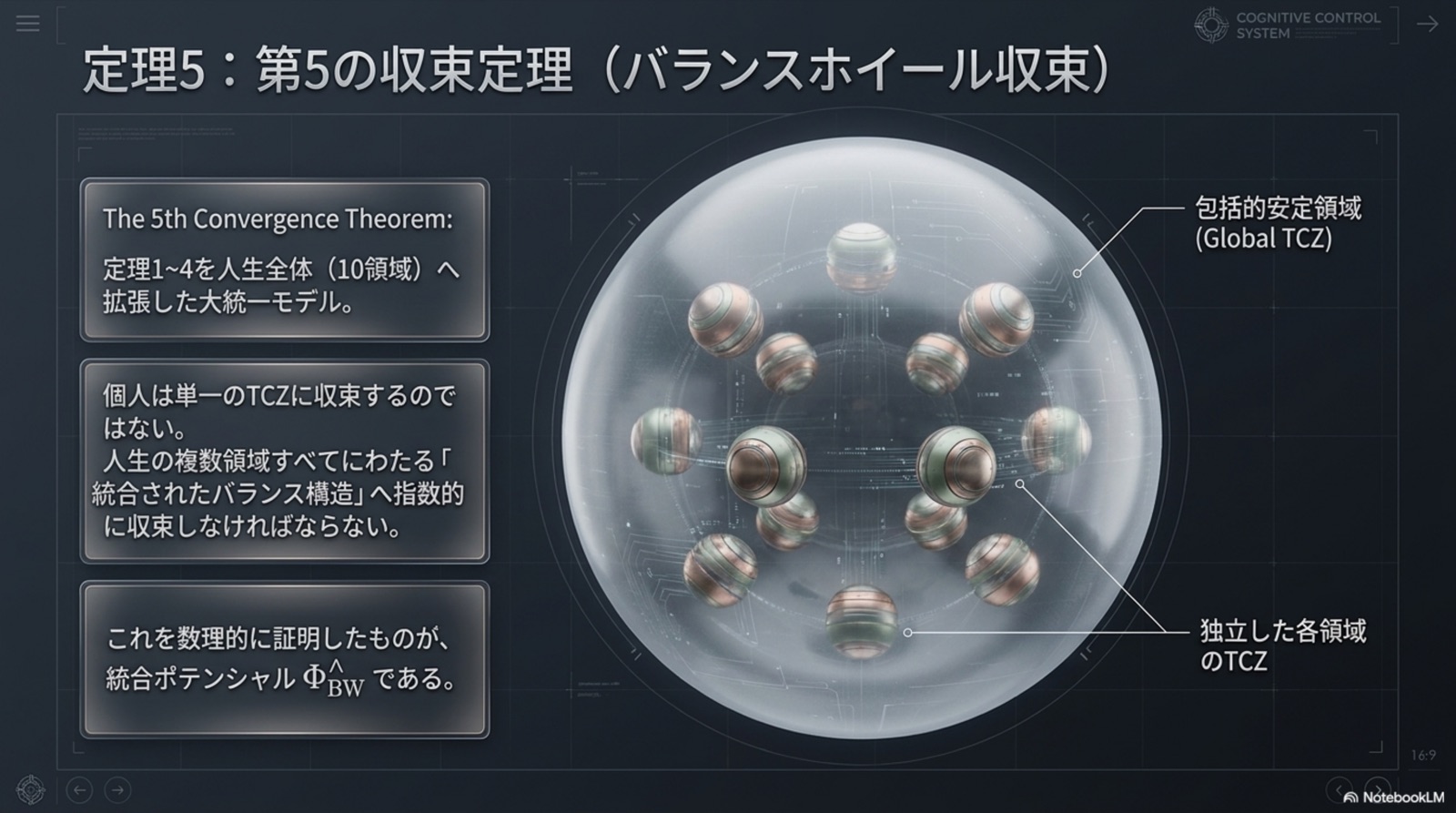
バランスホイール収束
ż = FBW(z, t), z = (x, G)
Φ = Φ̂BW (4項統合)
人生10領域同時バランス
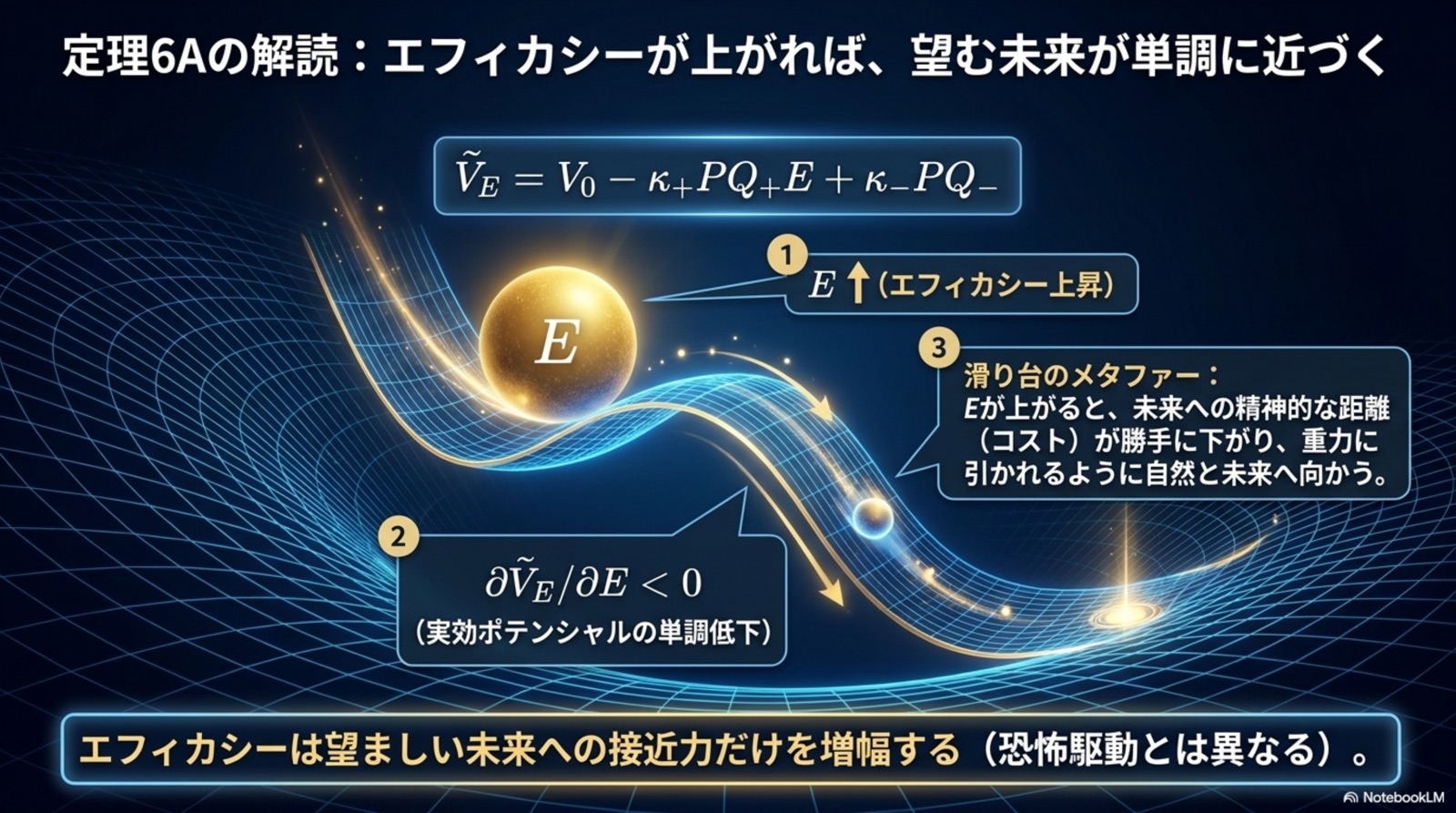
6A
エフィカシー加重ゴール収束
π_cE = arg min ∫ Ṽ_E dt
Φ = ṼE
E↑で望ましい未来が単調に近づく
6B
Collective Efficacy 収束
dE_i/dt = (1−E_i)[ρ B + ΣγCE]
Φ = ΨE
全員 Ei → 1 へ指数収束
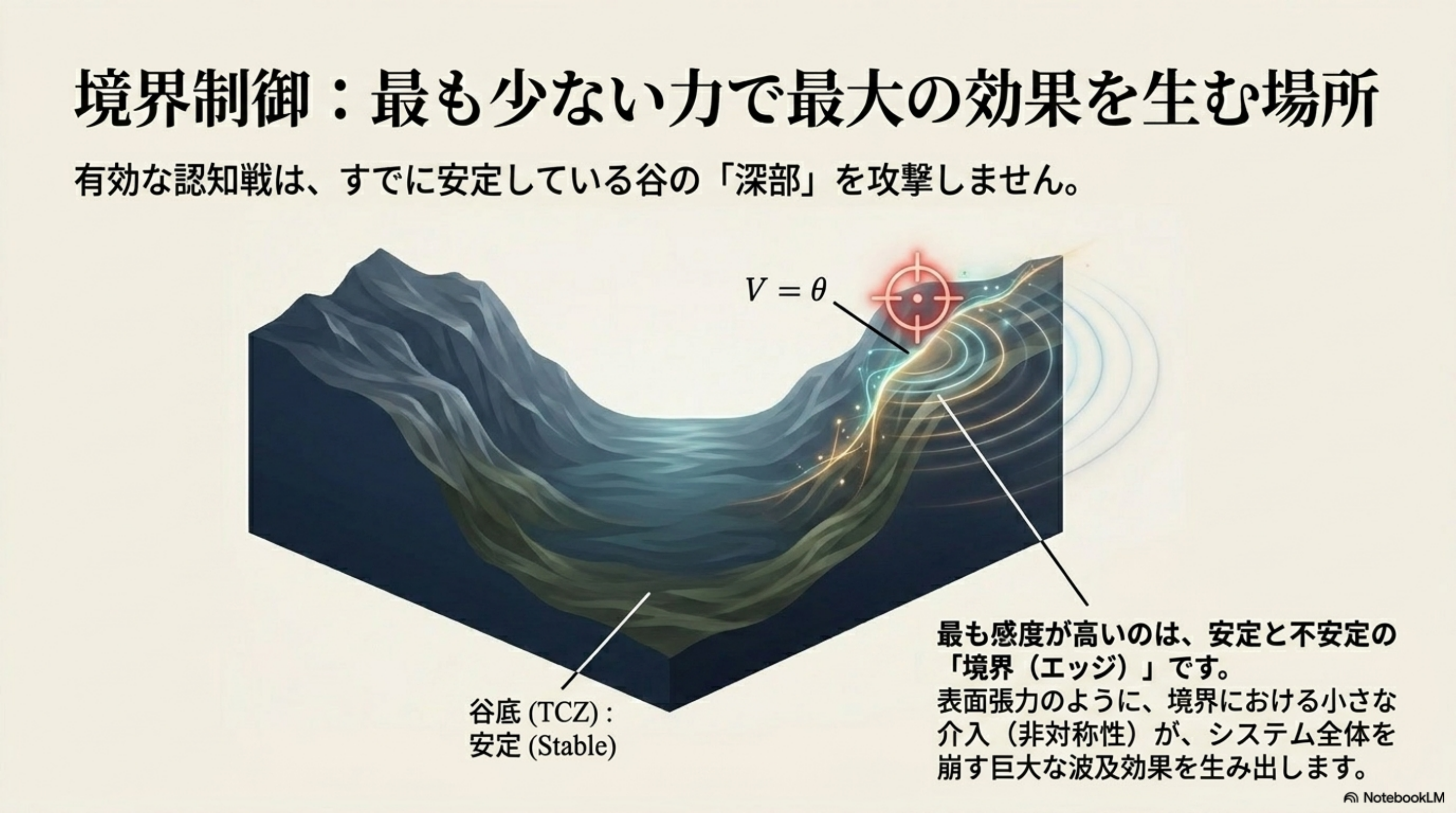
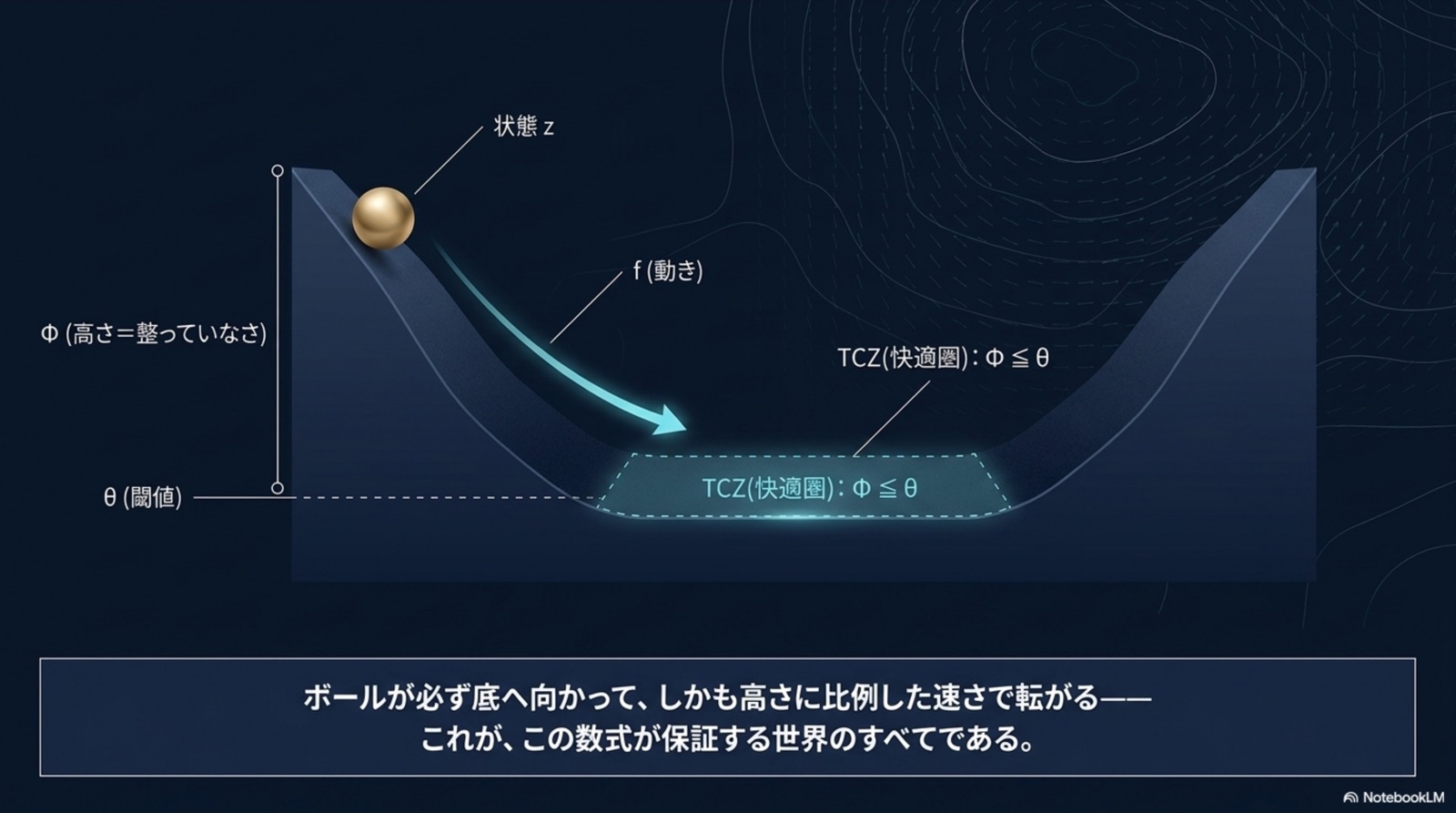
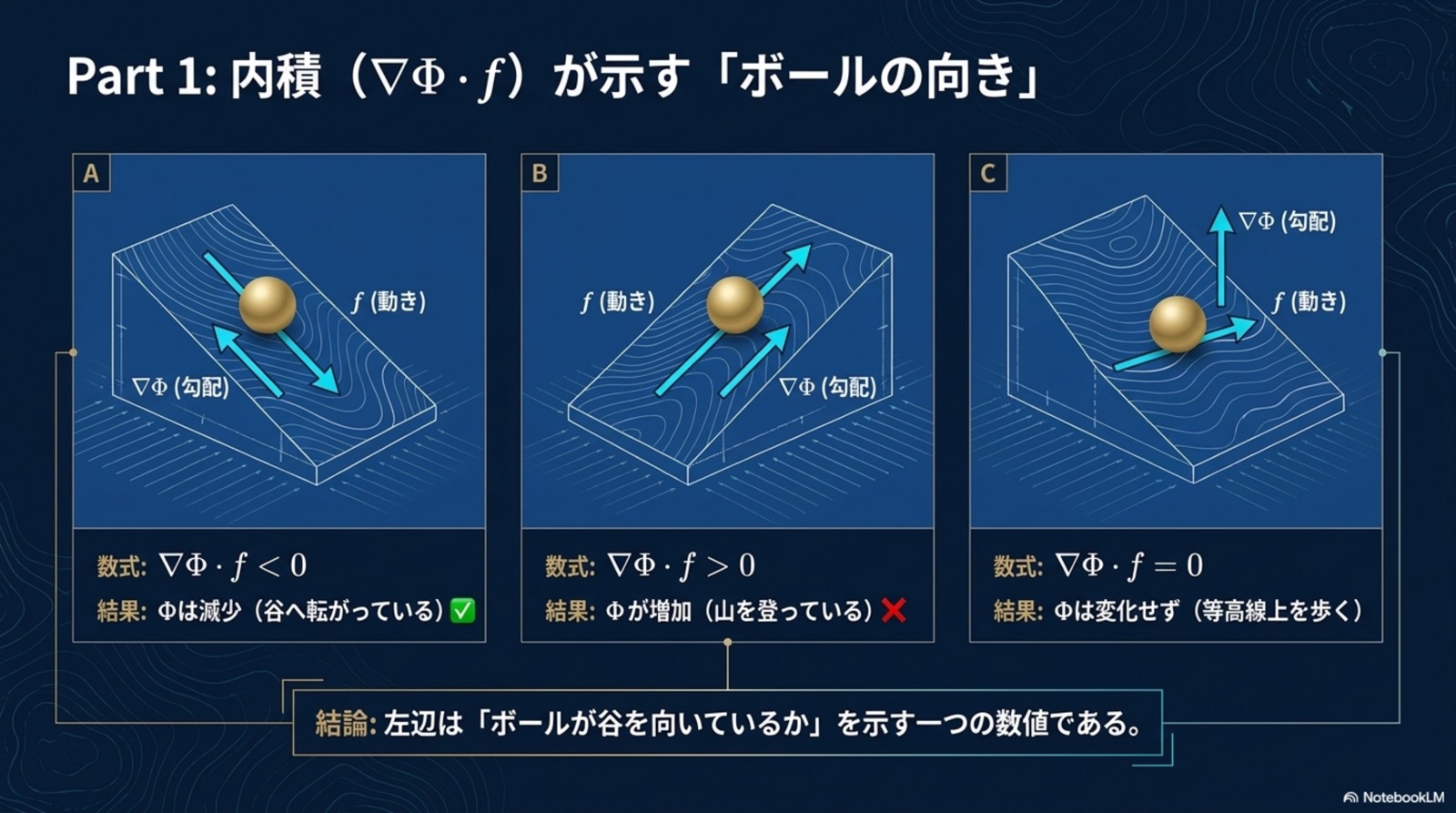
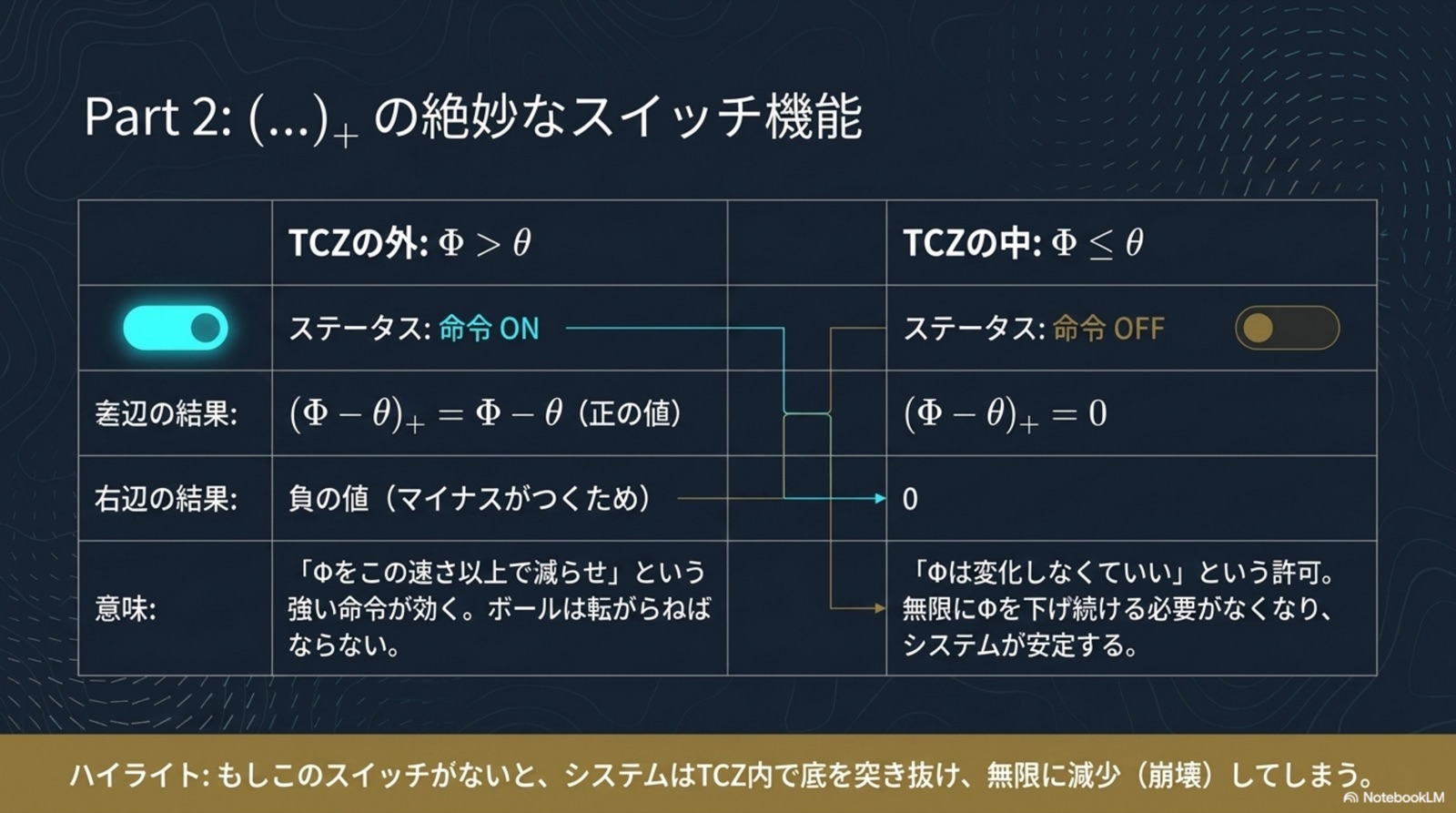
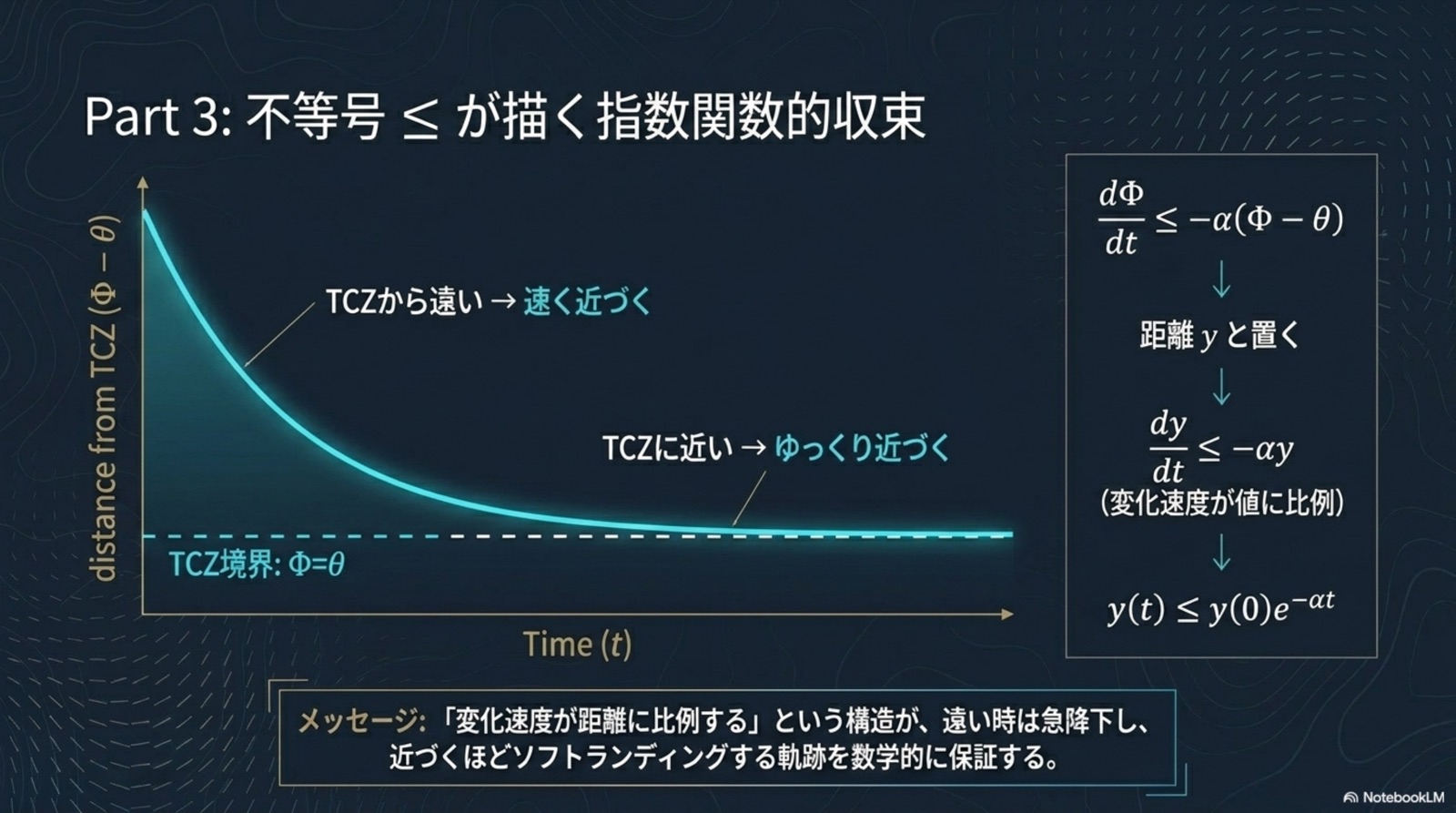
統一原理(B.6): すべての定理は、単一の B.1 統一補題(指数収束保証)の特殊化である。差異は「何を Lyapunov 関数として選ぶか」のみ。収束機構は完全に共通。